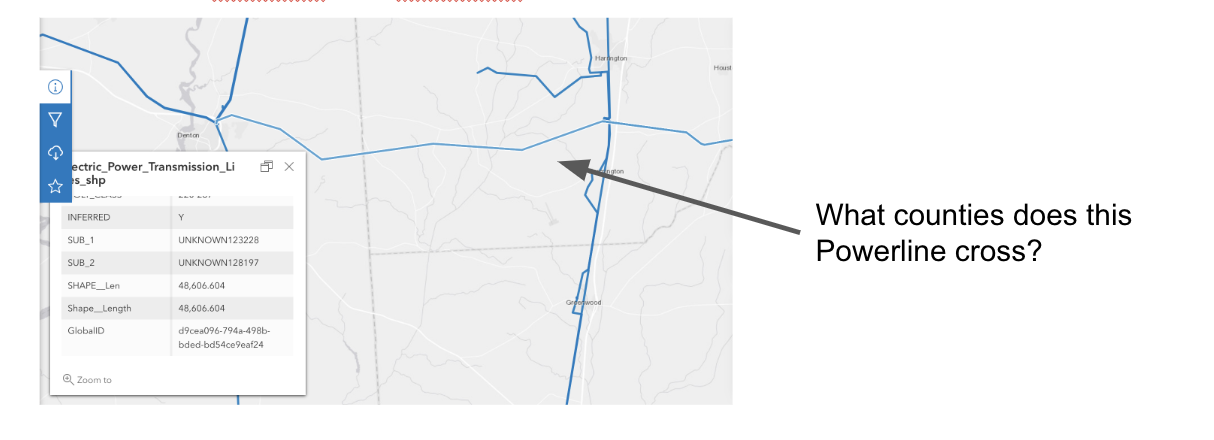
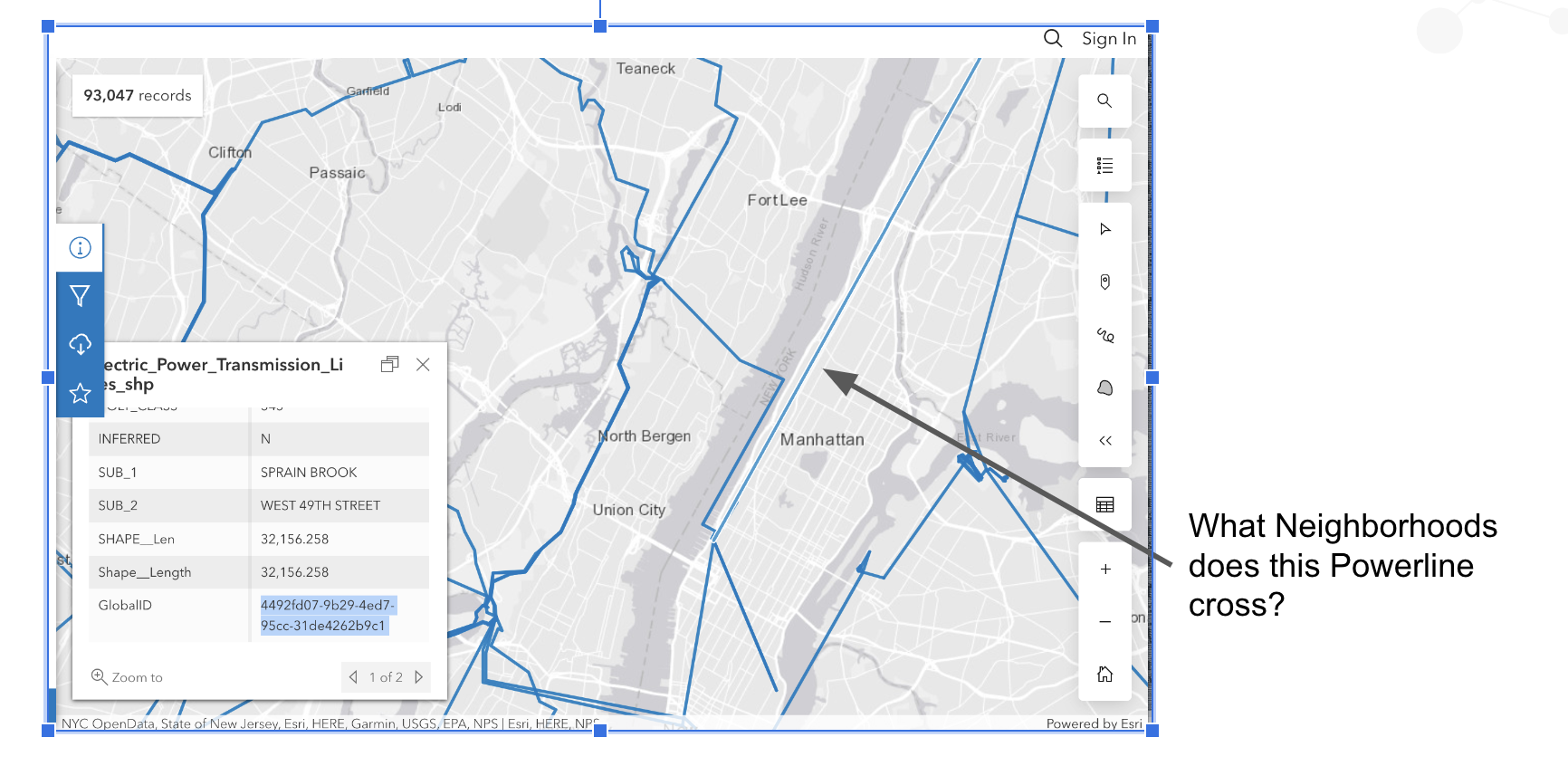
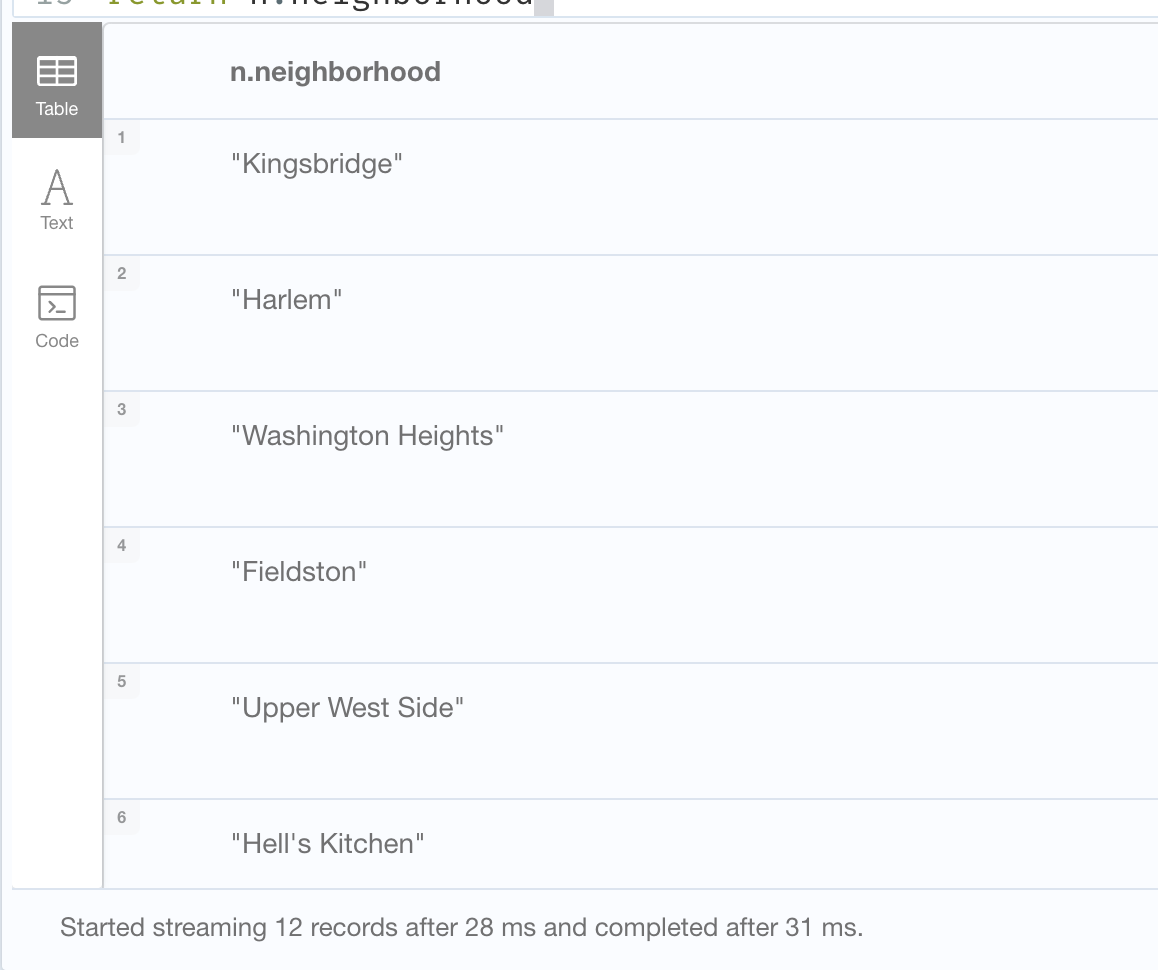
In this series (post 1 and post 2), we talked about using Neo4j plus a Vector Index plus H3 indexing to attempt to do some geospatial pre-filtering on the Foursquare Open Source Places (FSQ OS Places) dataset. In this post, we will create some queries that leverage the vector index within Neo4j combined with H3 indexing for geo-filtering to find nearby points-of-interest (POIs). This example does not leverage an LLM or AI but it could easily be added.
Data Model Review
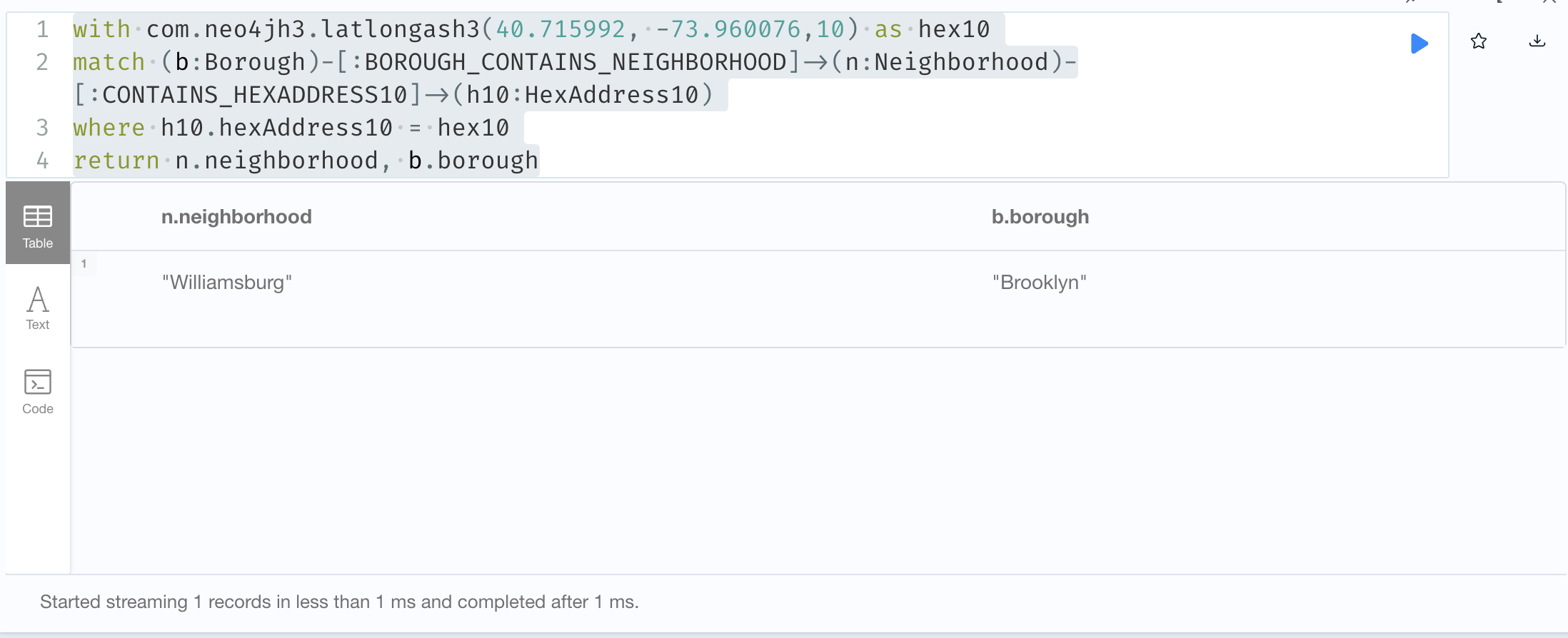
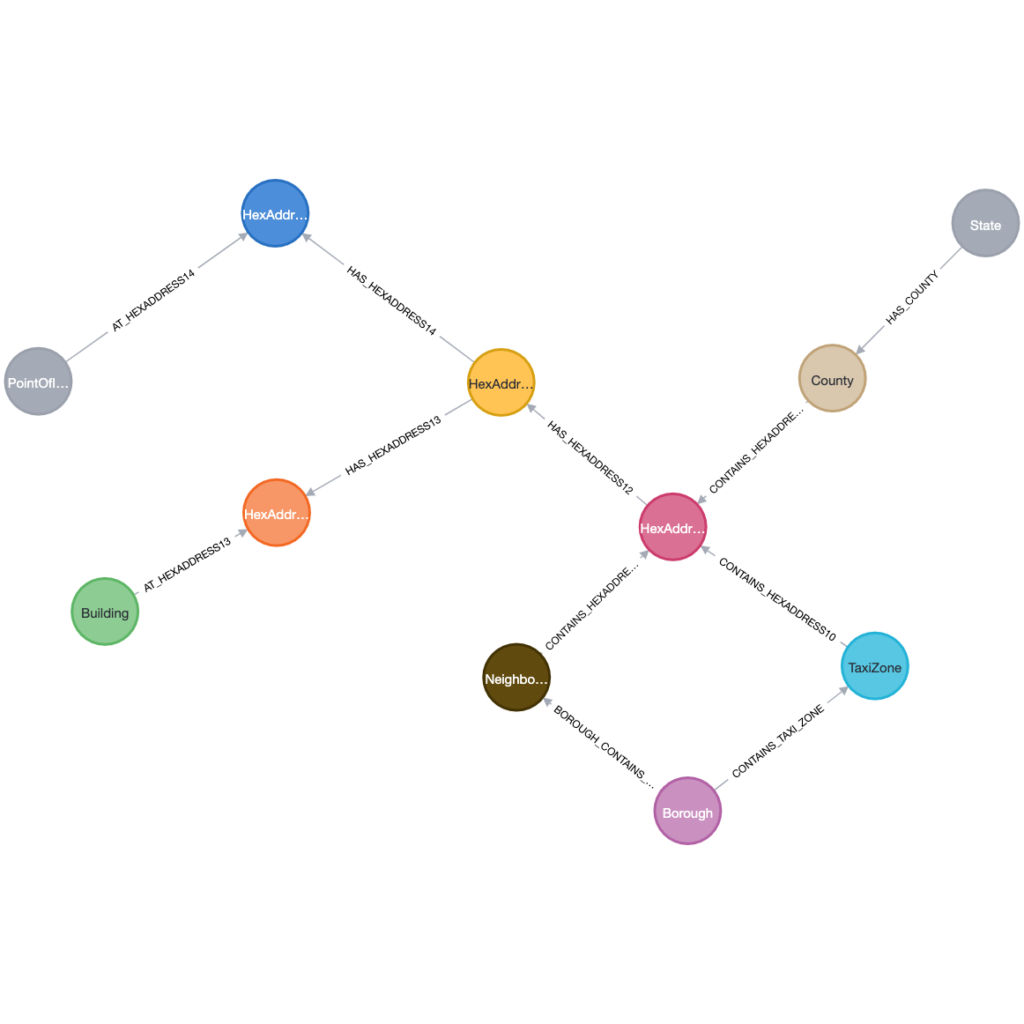
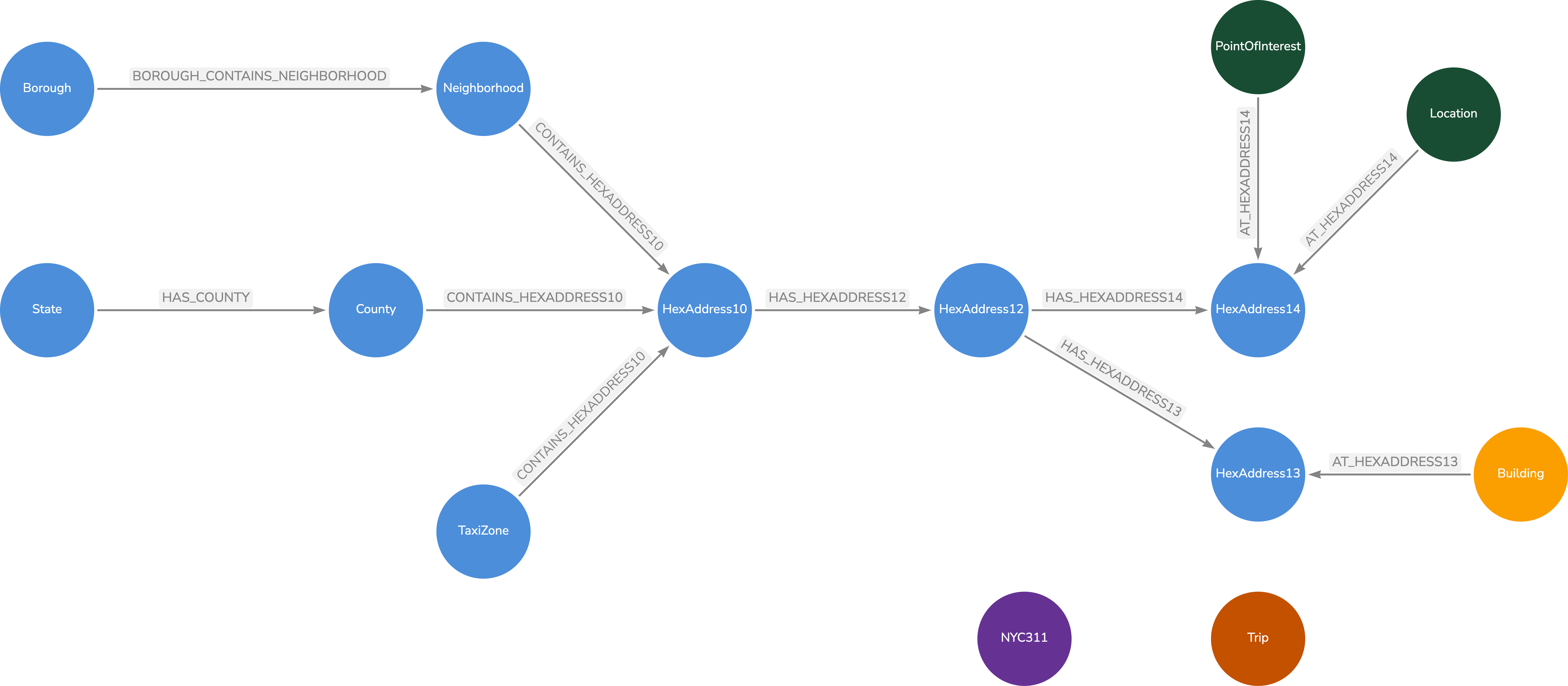
To review, we have the POIs modeled where they are in a hierarchy of categories. Each category name has an embedded vector of 768 dimensions. Each POI also has a 768 dimension vector that was created from its

We then have our Geospatial Knowledge Graph (GKG) that contains our reference geospatial data. We have also created 768 dimension vectors for the geospatial names of City, State, County, Borough and TaxiZone nodes.

By having both databases, we are able to search by both a Category name and a Geospatial name. We can leverage the vector index to find the category name(s) and also leverage the vector index to find a set of geospatial places. Since we have H3 index values for both the POI and the geospatial name, we can then find the overlap and return our POIs.
Workflow
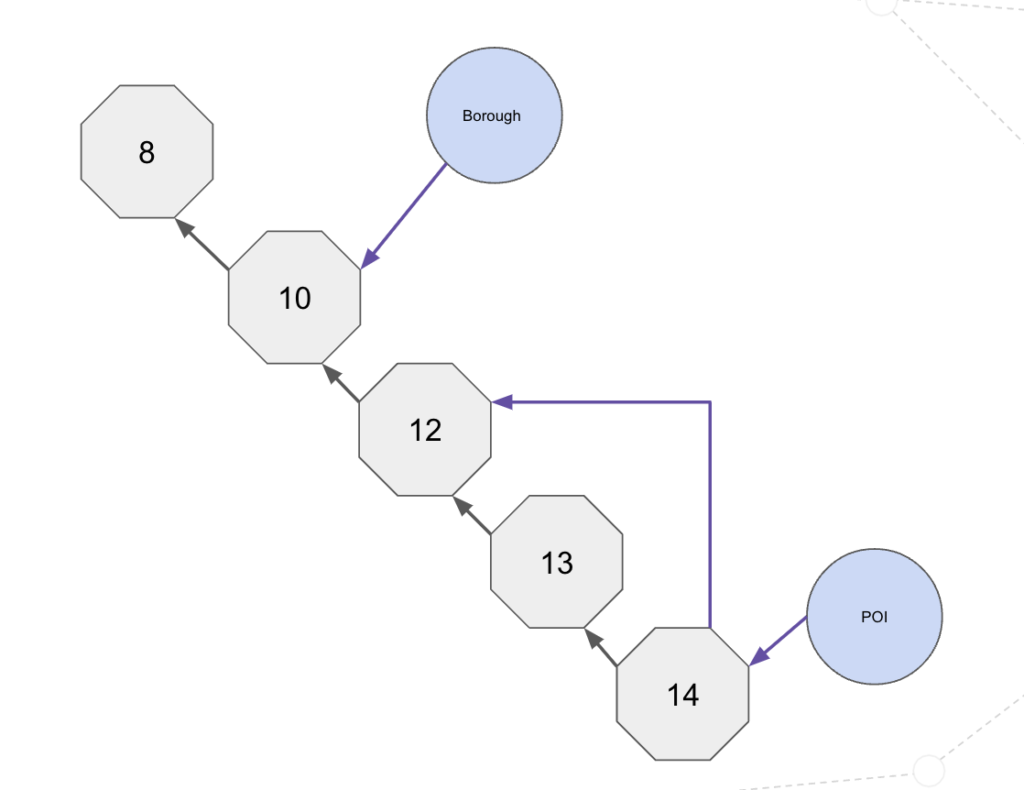
Our workflow is shown below:

The steps that we are following are:
- Enter a desired geolocation (i.e. a City name) and create a vector for that name.
- Enter a desired category (i.e. Grocery Store) and create a vector for the category name.
- Search the GKG for the places that match the vector. For the 50 places, return their associated H3 values.
- Search the POI graph for the top 150 categories that match the category vector.
- Identify the POIs that are contained within the categories and where their H3 value is within the GKG set of H3 values.
Code
In our code, we are using the SentenceTransformer to create the vectors for the city name and the category name. Let’s look at this block of code from our workbook.
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v1')
cityName = input("Search City ")
categoryName = input("Category Name ")
cityArray=[]
categoryArray=[]
cityArray.append(cityName)
categoryArray.append(categoryName)
cityEmbeddings = model.encode(cityArray)
categoryEmbeddings = model.encode(categoryArray)
cityEmbedding = cityEmbeddings[0]
categoryEmbedding = categoryEmbeddings[0]
cityCount=50
poiCount=150
POIs = gdscdb.run_cypher("""
CALL () {USE geovectordemo.geokb CALL db.index.vector.queryNodes('geoNameVectorIndex', $CITYRESULTS, $CITYEMBEDDING) YIELD node as n,score with n match (n)-[:IN_HEXADDRESS_8]->(h:HexAddress8) return collect(h.hexAddress8) as ha8 } with ha8 CALL (ha8) { USE geovectordemo.poi CALL db.index.vector.queryNodes('categoryVectorIndex', $POIRESULTS, $CATEGORYEMBEDDING) YIELD node with node as category match (category)<-[:IS_IN_CATEGORY]-(p:POI) where p.hexAddress8 in ha8 return p.name as name, p.country as country, coalesce(p.locality,'n/a') as locality, p.latitude as Latitude, p.longitude as Longitude limit 75} RETURN name,country, locality, Latitude, Longitude
""",
params={"CATEGORYEMBEDDING":categoryEmbedding,
"CITYRESULTS":cityCount,
"POIRESULTS":poiCount,
"CITYEMBEDDING":cityEmbedding
})
POIsHere are sample results from entering Richmond as the city and Grocery Store as the category.

This runs in sub-second as we can identify the POIs connected to a category and then join / filter based on the H3 address.
If we build a vector based on two categories, we can still identify results in under a second.
POIs = gdscdb.run_cypher("""
CALL () {USE geovectordemo.geokb CALL db.index.vector.queryNodes('geoNameVectorIndex', $CITYRESULTS, $CITYEMBEDDING) YIELD node as n,score with n match (n)-[:IN_HEXADDRESS_8]->(h:HexAddress8) return collect(h.hexAddress8) as ha8 } with ha8 CALL (ha8) { USE geovectordemo.poi CALL { CALL db.index.vector.queryNodes('categoryVectorIndex', $POIRESULTS, $CATEGORYEMBEDDING) YIELD node RETURN node UNION CALL db.index.vector.queryNodes('categoryVectorIndex', $POIRESULTS, $CATEGORYEMBEDDINGTWO) YIELD node RETURN node } with node as category match (category)<-[:IS_IN_CATEGORY]-(p:POI) where p.hexAddress8 in ha8 return p.fsq_place_id as placeID, p.name as name, p.country as country, coalesce(p.locality,'n/a') as locality, p.latitude as Latitude, p.longitude as Longitude limit 75} RETURN placeID, name,country, locality, Latitude, Longitude
""",
params={"CATEGORYEMBEDDING":categoryEmbedding,
"CITYRESULTS":cityCount,
"POIRESULTS":poiCount,
"CITYEMBEDDING":cityEmbedding,
"CATEGORYEMBEDDINGTWO":categoryEmbeddingTwo
})
POIs
Summary
Filtering vector search results is a complex problem that is being addressed in different ways by different vector search providers. (Example 1 or Example 2). Vector index searches can be slow if we have to compare every entry with the source vector. In the approach that we have discussed, we are using the Location and the Category as our pre-filters to limit the search scope and return results in a relatively reasonable timeframe.
What happens if we just search on the POI name? Are there any approaches that we can take to optimize that search? We will investigate that in the last blog post of this series.