Neo4j has recently announced the 2.2 Milestone 2 release. Among the exciting features is the improved and fully integrated “Superfast Batch Loader”. This utility (unsurprisingly) called neo4j-import, now supports large scale non-transactional initial loads (of 10M to 10B+ elements) with sustained throughputs around 1M records (node or relationship or property) per second. Neo4j-import is available from the command line on both Windows and Unix.
In this post, I’ll walk through how to set up the data files, some command line options and then document the performance for importing a medium size data set.
The Physician and Other Supplier PUF contains information on utilization, payment (allowed amount and Medicare payment), and submitted charges organized by National Provider Identifier (NPI), Healthcare Common Procedure Coding System (HCPCS) code, and place of service. This PUF is based on information from CMS’s National Claims History Standard Analytic Files. The data in the Physician and Other Supplier PUF covers calendar year 2012 and contains 100% final-action physician/supplier Part B non-institutional line items for the Medicare fee-for-service population.
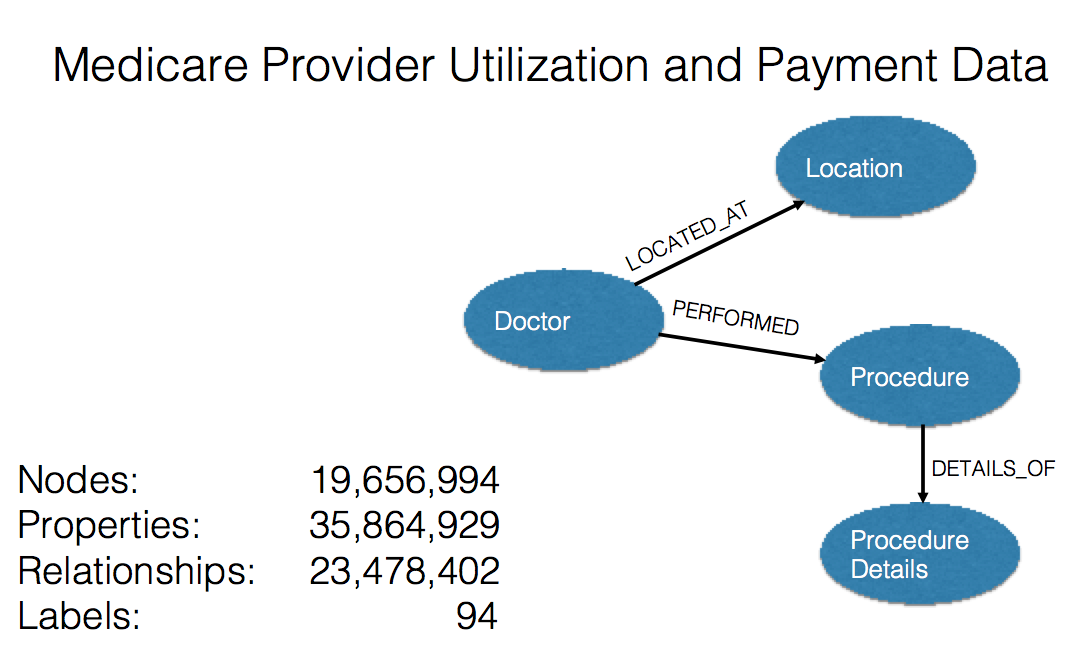
For the data model, I created doctor nodes, address nodes, procedure nodes and procedure detail nodes.
A (doctor)-[:LOCATED_AT]-(Address)
A (doctor)-[:PERFORMED]-(procedure)
A (procedure) -[:CONTAINS]-(procedure_details)
The model is shown below:
Import Tool Notes
The new neo4j-import tool has the following capabilities:
Fields default to be comma separated, but a different delimiter can be specified.
All files must use the same delimiter.
Multiple data sources can be used for both nodes and relationships.
A data source can optionally be provided using multiple files.
A header which provides information on the data fields must be on the first row of each data source.
Fields without corresponding information in the header will not be read.
UTF-8 encoding is used.
File Layouts
The header file must have an :ID and can have multiple properties and a :LABEL value. The :ID is a unique value that is used during node creation but more importantly is used during relationships creation. The :ID value is used later as the :START_ID or :END_ID value which are used to create the relationships. :ID values can be integers or strings as long as they are unique.
The :LABEL value is used to create the Label in the Property Graph. A label is a named graph construct that is used to group nodes into sets; all nodes labeled with the same label belongs to the same set.
For example:
:ID Name :LABEL NPI
2 ARDALAN ENKESHAFI Internal Medicine 1003000126
7 JENNIFER VELOTTA Obstetrics/Gynecology 1003000423
8 JACLYN EVANS Clinical Psychologist 1003000449
In this case, the :ID is the unique number, and the :LABEL column sets the doctor type. Name and NPI are property values added to the node.
The relationships file header contains a :START_ID, :END_ID and can optionally include properties and :TYPE. The :START_ID and the :END_ID link back to previously :ID values from the nodes files. The :TYPE is used to set the relationship type. All relationships in Neo4j have a relationship type.
Separate Header Files
It can be convenient to put the header in a separate file. This makes it easier to edit the header, as you avoid having to open a huge data file to just change the header. To use a separate header file in the command line, see the example below:
Under Unix/Linux/OSX, the command is named neo4j-import. Under Windows, the command is named Neo4jImport.bat.
Depending on the installation type, the tool is either available globally, or used by executing ./bin/neo4j-import or bin\Neo4jImport.bat from inside the installation directory.
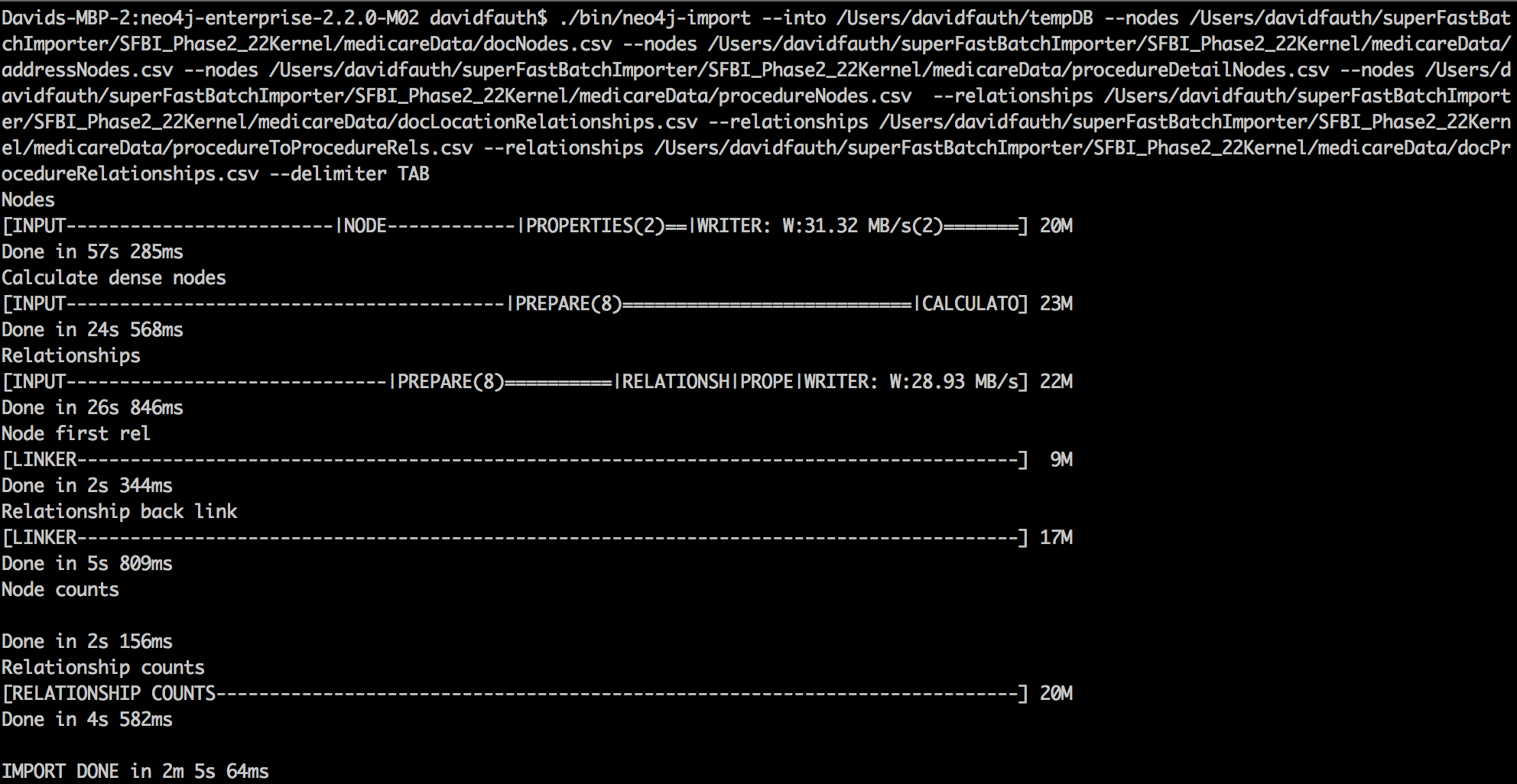
From the command line, we run the neo4j-import command. The –into option is used to indicate where to store the new database. The directory must not contain an existing database.
The –nodes option indicate the header and nodes files. Multiple –nodes can be used.
The –relationships option indicates the header and relationship files. Multiple –relationships can be used.
Running the load script on my 16GB Macbook Pro with an SSD, I was able to load 20.7M nodes, 23.4M relationships and 35.6M properties in 2 minutes and 5 seconds.
Conclusion
The new neo4j-import tool provides significant performance improvements and ease-of-use for the initial data loading of a Neo4j database. Please download the latest milestone release and give the neo4j-import tool a try.
We are eager to hear your feedback. Please post it to the Neo4j Google Group, or send us a direct email at feedback@neotechnology.com.
Using Mortar to read/write Parquet files
You can load Parquet formatted files into Mortar, or tell Mortar to output data in Parquet format using the Hadoop connectors that can be built from here or downloaded from here.
Last year, Cloudera, in collaboration with Twitter and others, released a new Apache Hadoop-friendly, binary, columnar file format called Parquet. Parquet is an open source serialization format that stores data in a binary column-oriented fashion. Instead of how row-oriented data is stored, where every column for a row is stored together and then followed by the next row (again with columns stored next to each other), Parquet turns things on its head. Instead, Parquet will take a group of records and store the values of the first column together for the entire row group, followed by the values of the second column, and so on. Parquet has optimizations for scanning individual columns, so it doesn’t have to read the entire row group if you are only interested in a subset of columns.
Installation:
In order to use parquet pig hadoop, the jar needs to be in Pig’s classpath. There are various ways of making that happen though typically the REGISTER command is used:
REGISTER /path/parquet-pig-bundle-1.5.0.jar;
the command expects a proper URI that can be found either on the local file-system or remotely. Typically it’s best to use a distributed file-system (like HDFS or Amazon S3) and use that since the script might be executed on various machines.
Loading Data from a Parquet file
As you would expect, loading the data is straight forward:
data = LOAD 's3n://my-s3-bucket/path/to/parquet'
USING parquet.pig.ParquetLoader
AS (a:chararray, b:chararray, c:chararray)
Writing data to a Parquet file
You can store the output of a Pigscript in Parquet format using the jar file as well.
Store result INTO 's3n://my-s3-bucket/path/to/output' USING parquet.pig.ParquetStorer.
Compression Options
You can select the compression to use when writing data with the parquet.compression property. For example
set parquet.compression=SNAPPY
The valid options for compression are:
UNCOMPRESSED
GZIP
SNAPPY
The default is SNAPPY
Simple examples of Mortar to Parquet and back
One of the advantages is that Parquet can compress data files. In this example, I downloaded the CMS Medicare Procedure set. This file is a CSV file that is 1.79GB in size. It contains 9,153,274 rows. I wrote a simple Pig script that loads the data, orders the data by the provider’s state and then write it back out as a pipe delimited text file and as a parquet file.
orderDocs = ORDER docs BY nppes_provider_state ASC PARALLEL 1;
STORE orderDocs INTO '$OUTPUT_PATH' USING PigStorage('|');
STORE orderDocs INTO '$PARQUET_OUTPUT_PATH' USING parquet.pig.ParquetStorer;
With the regular pipe delimited file, the file size is still 1.79GB in size. With parquet, the file is 838.6MB (a 53% reduction in size).
Another advantage is that you can take the resulting output of the file and copy it into an impala directory (/user/hive/warehouse/mortarP) for an existing Parquet formatted table. Once you refresh the table (refresh), the data is immediately available.
Finally, you can copy the parquet file from an Impala table to your local drive or to an S3 bucket, connect to it with Mortar and work directly with the data.
parquetData = LOAD '/Users/davidfauth/vabusinesses/part-m-00000.gz.parquet' USING parquet.pig.ParquetLoader AS
(corp_status_date:chararray,
corp_ra_city:chararray,
corp_name:chararray);
If we illustrate this job, we see that we see the resulting data sets.
Using Mortar and Parquet provides additional flexibility when dealing with large data sets.
The Centers for Medicare and Medicaid Services made a huge announcement on Wednesday. By mid-next week (April 9th), they will be releasing a massive database on the payments made to 880,000 health care professionals serving seniors and the disabled in the Medicare program, officials said this afternoon.
The data will cover doctors and other practitioners in every state, who collectively received $77 billion in payments in 2012 in Medicare’s Part B program. The information will include physicians’ provider IDs, their charges, their patient volumes and what Medicare actually paid. “With this data, it will be possible to conduct a wide range of analyses that compare 6,000 different types of services and procedures provided, as well as payments received by individual health care providers,” Jonathan Blum, principal deputy administrator of the Centers for Medicare and Medicaid Services, wrote in a blog post on Wednesday, April 3rd.
So get your Hadoop clusters ready, fire up R or other tools and be ready to look at the data.
I’m starting a new series on analyzing publicly available large data sets using Mortar. In the series, I will walk through the steps of obtaining the data sets, writing some Pig scripts to join and massage the data sets, adding in some UDFs that perform statistical functions on the data and then plotting those results to see what the data shows us.
Recently, the HHS released a new, improved update of the DocGraph Edge data set. As the DocGraph.org website says, “This is not just an update, but a dramatic improvement in what data is available.” The improvement in the data set is that we know how many patients are in the patient sharing relationship as shown in the new data structure:
Again, from the DocGraph.org website, “The PatientTotal field is the total number of the patients involved in a treatment event (a healthcare transaction), which means that you can now tell the difference between high transaction providers (lots of transactions on few patients) and high patient flow providers (a few transactions each but on lots of patients)”.
Data Sets
HHS released “data windows” for 30 days, 60 days, 90 days, 180 days and 365 days. The time period is between 2012 and the middle of 2013. The number of edges or relationships is as follows:
Window
Edge Count
30 day
73 Million Edges
60 day
93 Million Edges
90 day
107 Million Edges
180 day
132 Million Edges
365 day
154 Million Edges
NPPES
The Administrative Simplification provisions of the Health Insurance Portability and Accountability Act of 1996 (HIPAA) mandated the adoption of standard unique identifiers for health care providers and health plans. The purpose of these provisions is to improve the efficiency and effectiveness of the electronic transmission of health information. The Centers for Medicare & Medicaid Services (CMS) has developed the National Plan and Provider Enumeration System (NPPES) to assign these unique identifiers.
NUCC Taxonomy Data
The Health Care Provider Taxonomy code set is an external, nonmedical data code set designed for use in an electronic environment, specifically within the ASC X12N Health Care transactions. This includes the transactions mandated under HIPAA.
The Health Care Provider Taxonomy code is a unique alphanumeric code, ten characters in length. The code set is structured into three distinct “Levels” including Provider Type, Classification, and Area of Specialization.
The National Uniform Claim Committee (NUCC) is presently maintaining the code set. It is used in transactions specified in HIPAA and the National Provider Identifier (NPI) application for enumeration. Effective 2001, the NUCC took over the administration of the code set. Ongoing duties, including processing taxonomy code requests and maintenance of the code set, fall under the NUCC Code Subcommittee.
Why Do I run Mortar
I use Mortar primarily for four reasons:
1. I can run Hadoop jobs on a large set that I can’t run on my laptop. For example, my MBP laptop with 8GB ram and an SSD can work with 73M records. However, when I start joining records and running large number of map reduce jobs, I am going to run out of temporary space on the hard drive. I can’t fully analyze the data sets.
2. It is easy to develop on my laptop and then deploy to a large Amazon cluster with a single command. The framework gives me Pig and Hadoop on my laptop with no configuration, version control through Github and the 1-button deployment. Mortar integrates easily with Amazon S3 so I can store these large data files in an S3 bucket and not worry about running out of space.
3. For debugging Pig scripts, Mortar has incorporated lipstick. Lipstick shows what the pigscript is doing in real time, provides samples of data and metrics along the way to help debug any issues that arise.
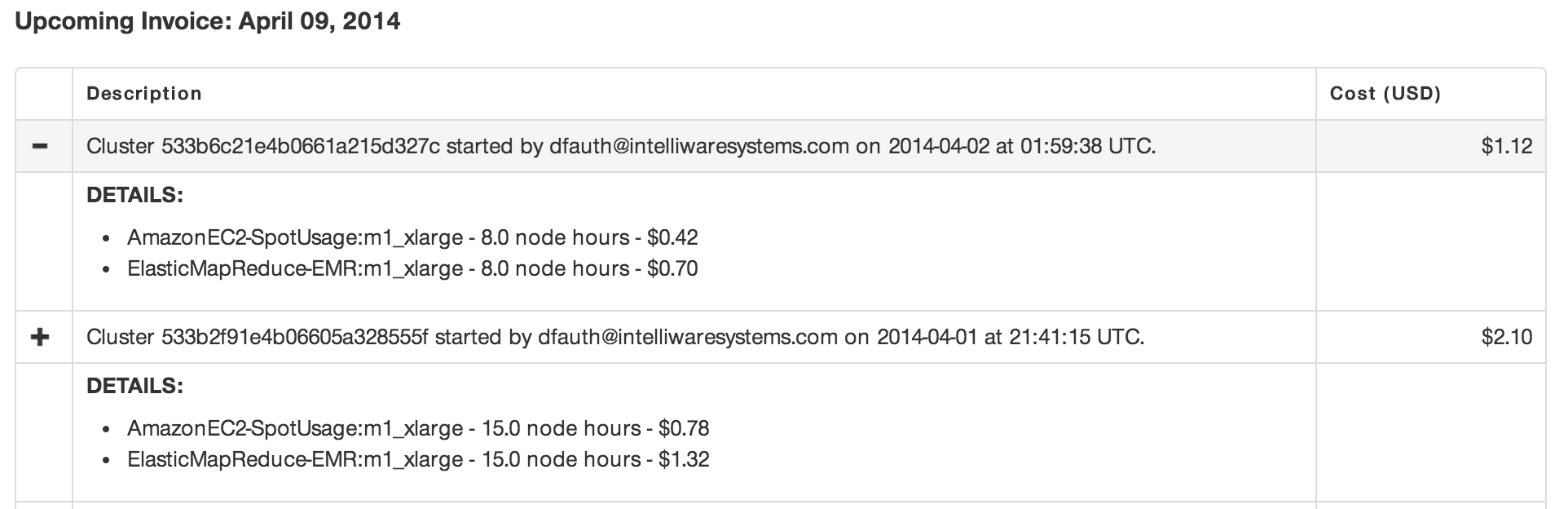
4. Cost. Using Amazon spot instances, I can process the data on a large cluster for less than the cost of a grande cup of coffee. Check out my invoice.
I ran an eight-node cluster for over an hour to process 73M records creating quartiles across three groups for $1.12. You can’t beat that.
Data Processing
The rest of the post will discuss processing the data sets. The HHS data sets are CSV files that have been zipped and stored on the docgraph.org site. In order to get information about the provider, I used the most current NPI data set (also known as the NPPES Downloadable File). This file contains information about the provider based on the National Provider Index (NPI). It is also a CSV file. Finally for the taxonomy, I used the Health Care Provider Taxonomy code set.
Each of these data sets are CSV files so there isn’t any data modification/transformation needed. I downloaded the files, unzipped them and uploaded them to an Amazon S3 bucket.
The desired data structure was to create a single row consisting of the following data elements:
This data structure allows me to perform various groupings of the data and derive statistical measures on the data.
The Pig code to create the structure is shown in the following gist.
Using Pig Functions and a UDF
For this blog post, I wanted to take a look at creating quartiles of different groups of data. I wanted to group the data by referring state and taxonomy, referred to state and taxonomy and finally referring taxonomy and referred to taxonomy.
For the median and quantiles of the data, we will use the Apache DataFu library. DataFu is a collection of Pig algorithms released by LinkedIn. The getting started page has a link to the JAR file which needs to be downloaded and registered with Pig. The statistics page shows us how we can use the median and the quantiles function. Both functions operate on a bag which we easily create using the Group function.
Once registered, we calculate the statistics as follows:
--calculate Avg, quartiles and medians
costsReferralsByStateTaxonomy = FOREACH referralsByStateTaxonomy GENERATE FLATTEN(group),
COUNT(prunedDocGraphRXData.sharedTransactionCount) as countSharedTransactionCount,
COUNT(prunedDocGraphRXData.patientTotal) as countPatientTotal,
COUNT(prunedDocGraphRXData.sameDayTotal) as countSameDayTotal,
SUM(prunedDocGraphRXData.sharedTransactionCount) as sumSharedTransactionCount,
SUM(prunedDocGraphRXData.patientTotal) as sumPatientTotal,
SUM(prunedDocGraphRXData.sameDayTotal) as sumSameDayTotal,
AVG(prunedDocGraphRXData.sharedTransactionCount) as avgSharedTransactionCount,
AVG(prunedDocGraphRXData.patientTotal) as avgPatientTotal,
AVG(prunedDocGraphRXData.sameDayTotal) as avgSameDayTotal,
Quartile(prunedDocGraphRXData.sharedTransactionCount) as stc_quartiles,
Quartile(prunedDocGraphRXData.patientTotal) as pt_quartiles,
Quartile(prunedDocGraphRXData.sameDayTotal) as sdt_quartiles,
Median(prunedDocGraphRXData.sharedTransactionCount) as stc_median,
Median(prunedDocGraphRXData.patientTotal) as pt_median,
Median(prunedDocGraphRXData.sameDayTotal) as sdt_median;
At this point, the code is ready to go and we can give it a run.
Running in local mode
One of the great things about Mortar is that I can run my project locally on a smaller data set to verify that I’m getting the results I’m expecting. In this case, I added a filter to the DocGraph data file and filtered out all records where the SameDayTotal was less than 5000. This allowed me to run the job locally using this command:
While running, I can use Mortar’s lipstick to visualize the running job as shown below:
Once the job completed after about an hour, the output format looks like this. From here, we can take this data and make some box plots to look at the data.
Closing Thoughts
Leveraging frameworks like the Amazon and Mortar allows someone like myself to perform large scale data manipulation at low cost. It allows me to be more agile and able to manipulate data in various ways to meet the need and provides the beginnings of self-service business intelligence.
Back in December, I wrote about some ways of moving data from Hadoop into Neo4J using Pig, Py2Neo and Neo4J. Overall, it was successful although maybe not at the scale I would have liked. So this is really attempt number two at using Hadoop technology to populate a Neo4J instance.
In this post, I’ll use a combination of Neo4J’s batchInserter plus JDBC to query against Cloudera’s Impala which in turn queries against files on HDFS. We’ll use a list of 694,221 organizations that I had from previous docGraph work.
What is Cloudera Impala
A good overview of Impala is in this presentation on SlideShare. Impala provides interactive SQL, nearly ANSI-92 standard SQL queries and provides a JDBC connector allowing external tools to access Impala. Cloudera Impala is the industry’s leading massively parallel processing (MPP) SQL query engine that runs natively in Apache Hadoop. The Apache-licensed, open source Impala project combines modern, scalable parallel database technology with the power of Hadoop, enabling users to directly query data stored in HDFS and Apache HBase without requiring data movement or transformation.
Installing a Hadoop Cluster
For this demonstration, we will use the Cloudera QuickStart VM running on VirtualBox. You can download the VM and run it in VMWare, KVM and VirtualBox. I chose VirtualBox. The VM gives you access to a working Impala instance without manually installing each of the components.
Sample Data
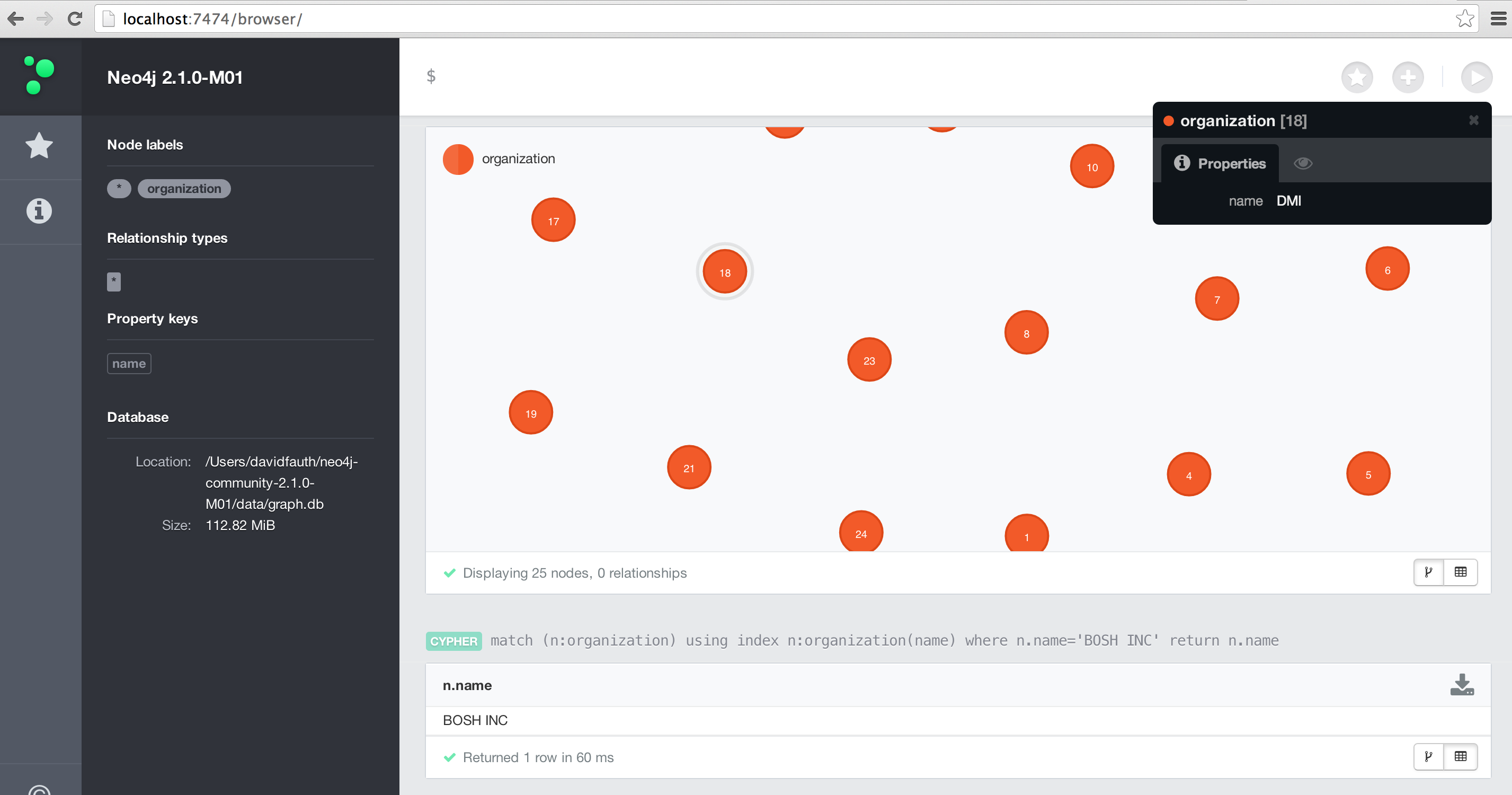
As mentioned above, the dataset is a list of 694,221 organizations that I had from previous docGraph work. Each organization is a single name that we will use to create organization nodes in Neo4J. An example is shown below:
BMH, INC
BNNC INC
BODYTEST
BOSH INC
BOST INC
BRAY INC
Creating a table
After starting the Cloudera VM, I logged into Cloudera Manager and made sure Impala was starting. Once Impala was up and running, I used the Impala Query Editor to create the table.
DROP TABLE if exists organizations;
CREATE EXTERNAL TABLE organizations
(c_orgname string)
row format delimited fields terminated by '|';
This creates an organizations table with a single c_orgname column.
Populating the Table
Populating the Impala table is really easy. After copying the source text file to the VM and dropping it into an HDFS directory, I ran the following command in the Impala query interface:
load data inpath '/user/hive/dsf/sample/organizationlist1.csv' into table organizations;
I had three organization list files. When I was done, I did a “Select * from organizations” resulting in a count of 694,221 records.
Querying the table
Cloudera provides a page on the JDBC driver. This page enables you to download the JDBC driver as well as points you to a GitHub page with a sample Java program for querying against Impala.
Populating Neo4J with BatchInserter and JDBC
While there are a multitude of ways of populating Neo4J, in this case I modified an existing program that I had written around the BatchInserter to populate Neo4J. The code can be browsed on Github. The java code creates an empty Neo4J data directory. It then connects to Impala through JDBC and runs a query to get all of the organizations. The code then loops over the result set, determines if a node with the name exists and creates a node with the organizational name if the node did not previously exist.
Running the program over the 694,221 records in Impala, the Neo4J database was created in approximately 20 seconds. Once that is done, I copied the database files into my Neo4J instance and restarted.
Once inside of Neo4J, I can query on the data or visualize the information as shown below.
Summary
Impala’s JDBC driver combined with Neo4J’s BatchInserter provides an easy and fast way to populate a Neo4J instance. While this example doesn’t show relationships, you can easily modify the BatchInserter to create the relationships.
ProPublica announced the ProPublica Data Store. ProPublica is making available the data sets that they have used to power their analysis. The data sets are bucketed into Premium, FOIA data and external data sets. Premium data sets have been cleaned up, categorized and enhanced with data from other sources. FOIA data is raw data from FOIA requests and external data sets are links to non-ProPublica data sets.
The costs range from free for FOIA data to a range of pricing ($200-$10000) from premium data depending on whether you are a journalist or academic and the data set itself. While the FOIA data may be free, ProPublica has done a significant amount of work to bring value to the data sets. For example, the Medicare Part D Prescribing Data 2011 FOIA data is free but does not contain details on DEA numbers, classification of drugs by category and several calculations. You can download an example of the data to see the additional attributes surrounding the data.
The Centers for Medicare & Medicaid Services recently made Physician Referral Patterns for 2009, 2010 and 2011 available. The physician referral data was initially provided as a response to a Freedom of Information Act (FOIA) request. These files represent 3 years of data showing the number of referrals from one physician to another. For more details about the file contents, please see the Technical Requirements (http://downloads.cms.gov/FOIA/Data-Request-Physician-Referrals-Technical-Requirements.pdf) document posted along with the datasets. The 2009 physician referral patterns were the basis behind the initial DocGraph analysis.
Over the next few weeks, I’ll be diving in to this data and writing about my results.
Earlier this year, Sunlight foundation filed a lawsuit under the Freedom of Information Act. The lawsuit requested solication and award notices from FBO.gov. In November, Sunlight received over a decade’s worth of information and posted the information on-line for public downloading. I want to say a big thanks to Ginger McCall and Kaitlin Devine for the work that went into making this data available.
In the first part of this series, I looked at the data and munged the data into a workable set. Once I had the data in a workable set, I created some heatmap charts of the data looking at agencies and who they awarded contracts to. In part two of this series, I created some bubble charts looking at awards by Agency and also the most popular Awardees. In the third part of the series, I looked at awards by date and then displaying that information in a calendar view. Then we will look at the types of awards as well as some bi-grams in the descriptions of the awards.
Those efforts were time consuming and took a lot of manual work to create the visualizations. Maybe there is a simpler and easier way to look at the data. For this post, I wanted to see if Elasticsearch and their updated dashboard (Kibana) could help out.
MortarData to Elasticsearch
Around October of last year, Elasticsearch announced integration with Hadoop. “Using Elasticsearch in Hadoop has never been easier. Thanks to the deep API integration, interacting with Elasticsearch is similar to that of HDFS resources. And since Hadoop is more then just vanilla Map/Reduce, in elasticsearch-hadoop one will find support for Apache Hive, Apache Pig and Cascading in addition to plain Map/Reduce.”
Elasticsearch published the first milestone (1.3.0.M1) based on the new code-base that has been in the works for the last few months.
I decided to use MortarData to output the fields that I want to search, visualize and dynamically drill down. Back in October, Mortar was able to update their platform to allow Mortar to write out to Elasticsearch at scale. Using the Mortar platform, I wrote a pig script that was able to read in the FBO data and manipulate it as needed. I did neet to modify the output of the Posted Date and Contract Award Date to ensure I had a date/time format that looked like ‘2014-02-01T12:30:00-05:00’. I then wrote out the data directly to the Elasticsearch index. A sample of the code is shown below:
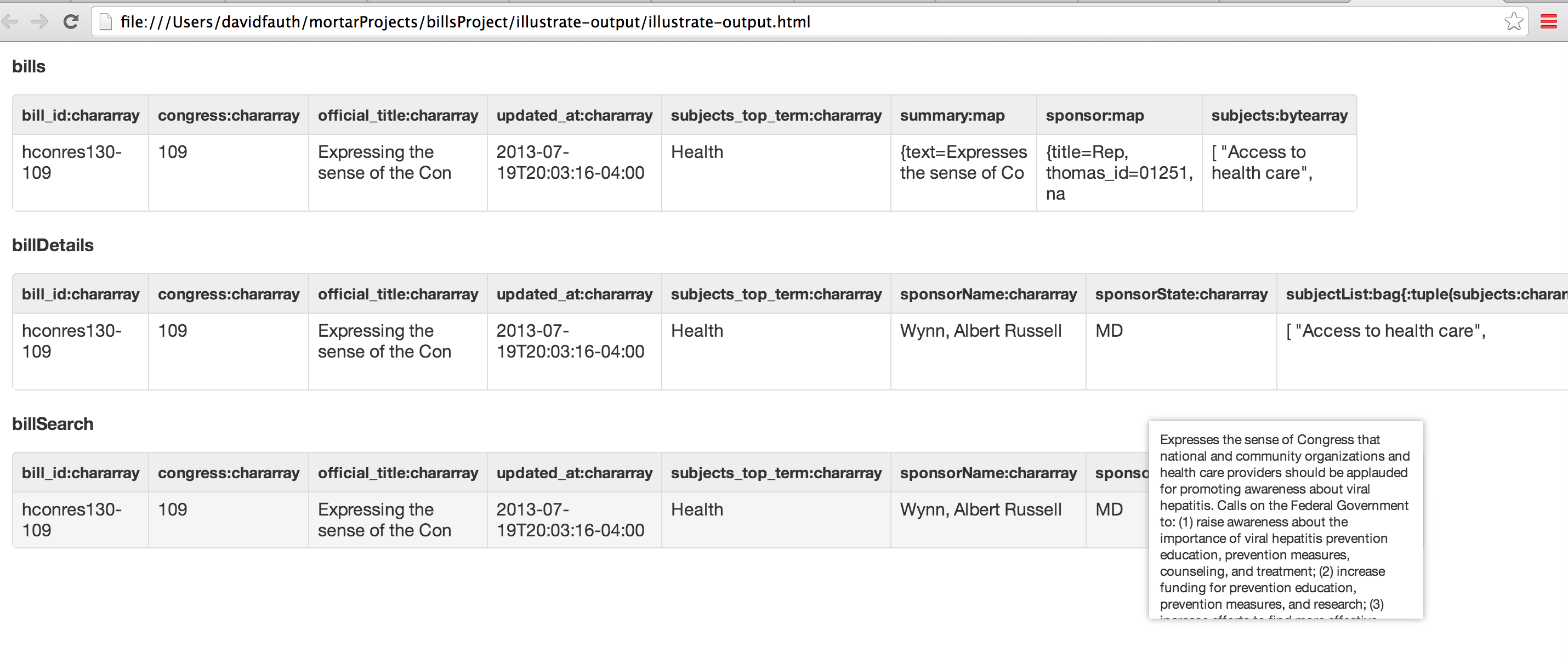
For GovTrack Bills data, it was a similar approach. I ensured the bill’s ‘Introduction Date’ was in the proper format and then wrote the data out to an Elasticsearch index. To ensure the output was correct, a quick illustration showed the proper dateformat.
After illustrating to verify the Pig script ran, I ran it on my laptop where it took about five minutes to process the FBO data. It took 54 seconds to process the GovTrack data.
Marvel
Elasticsearch just released Marvel. From the blog post,
“Marvel is a plugin for Elasticsearch that hooks into the heart of Elasticsearch clusters and immediately starts shipping statistics and change events. By default, these events are stored in the very same Elasticsearch cluster. However, you can send them to any other Elasticsearch cluster of your choice.
Once data is extracted and stored, the second aspect of Marvel kicks in – a set of dedicated dashboards built specifically to give both a clear overview of cluster status and to supply the tools needed to deep dive into the darkest corners of Elasticsearch.”
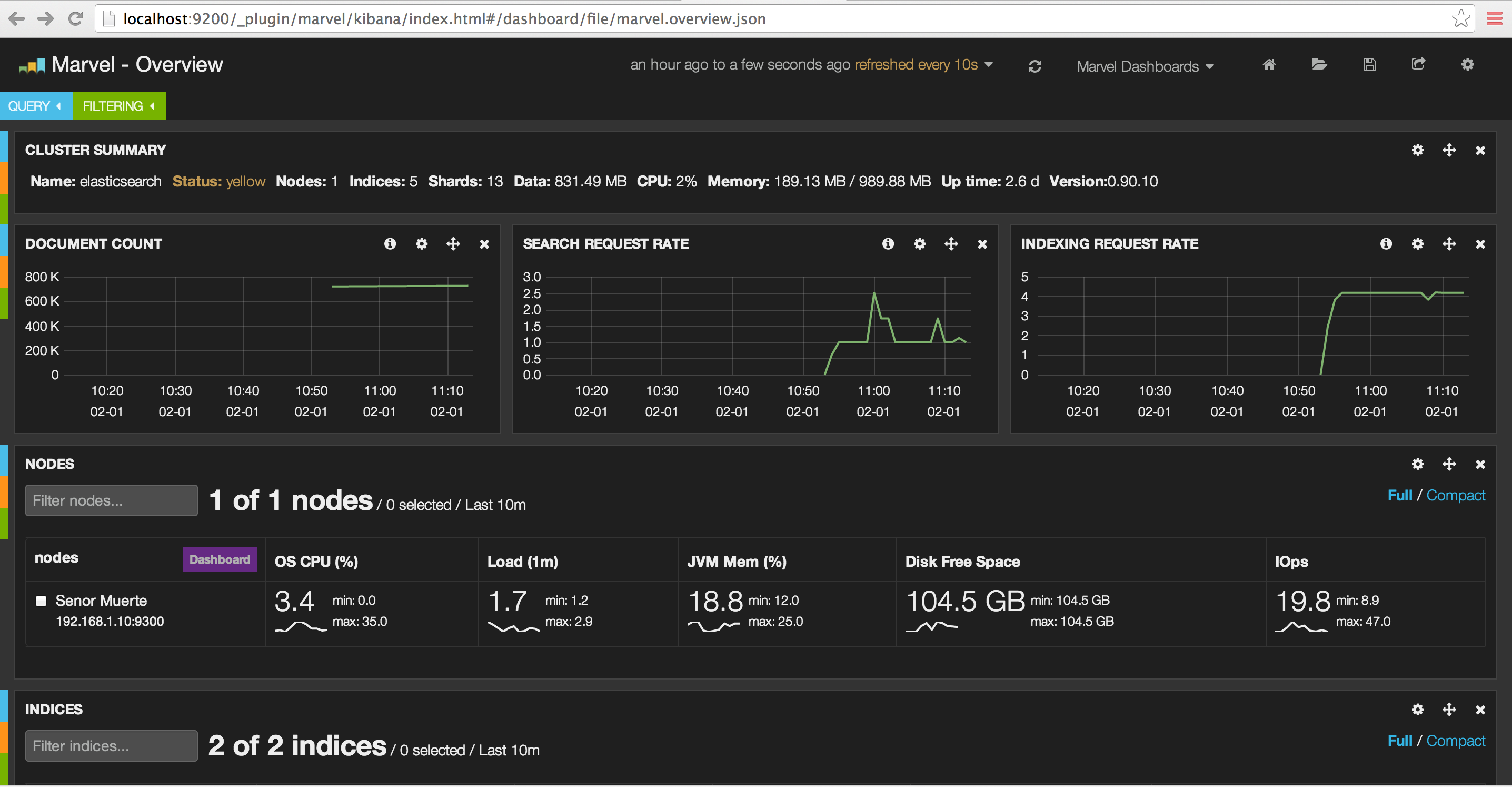
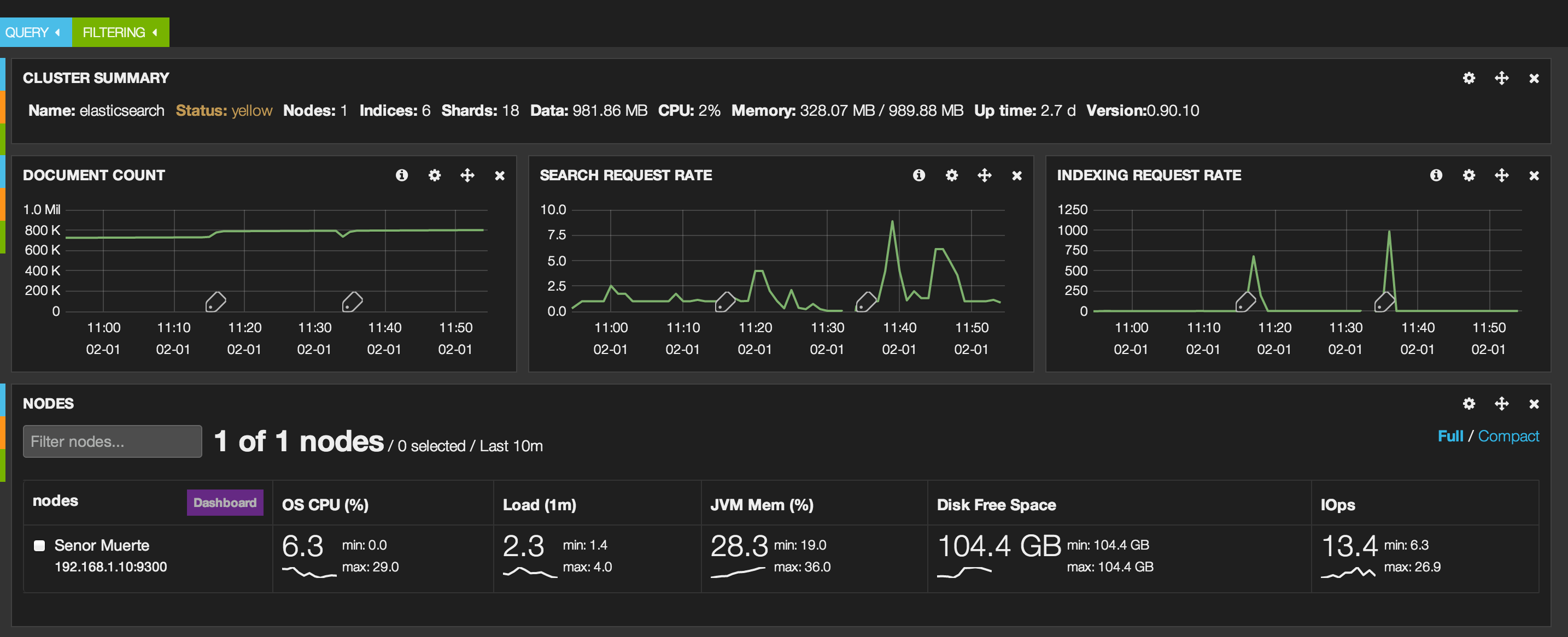
I had Marvel running while I loaded the GovTrack data. Let’s look at some screen captures to show the index being created, documents added, and then search request rate.
Before adding an index
This is a look at the Elasticsearch cluster before adding a new index. As you can see, we have two indexes created.
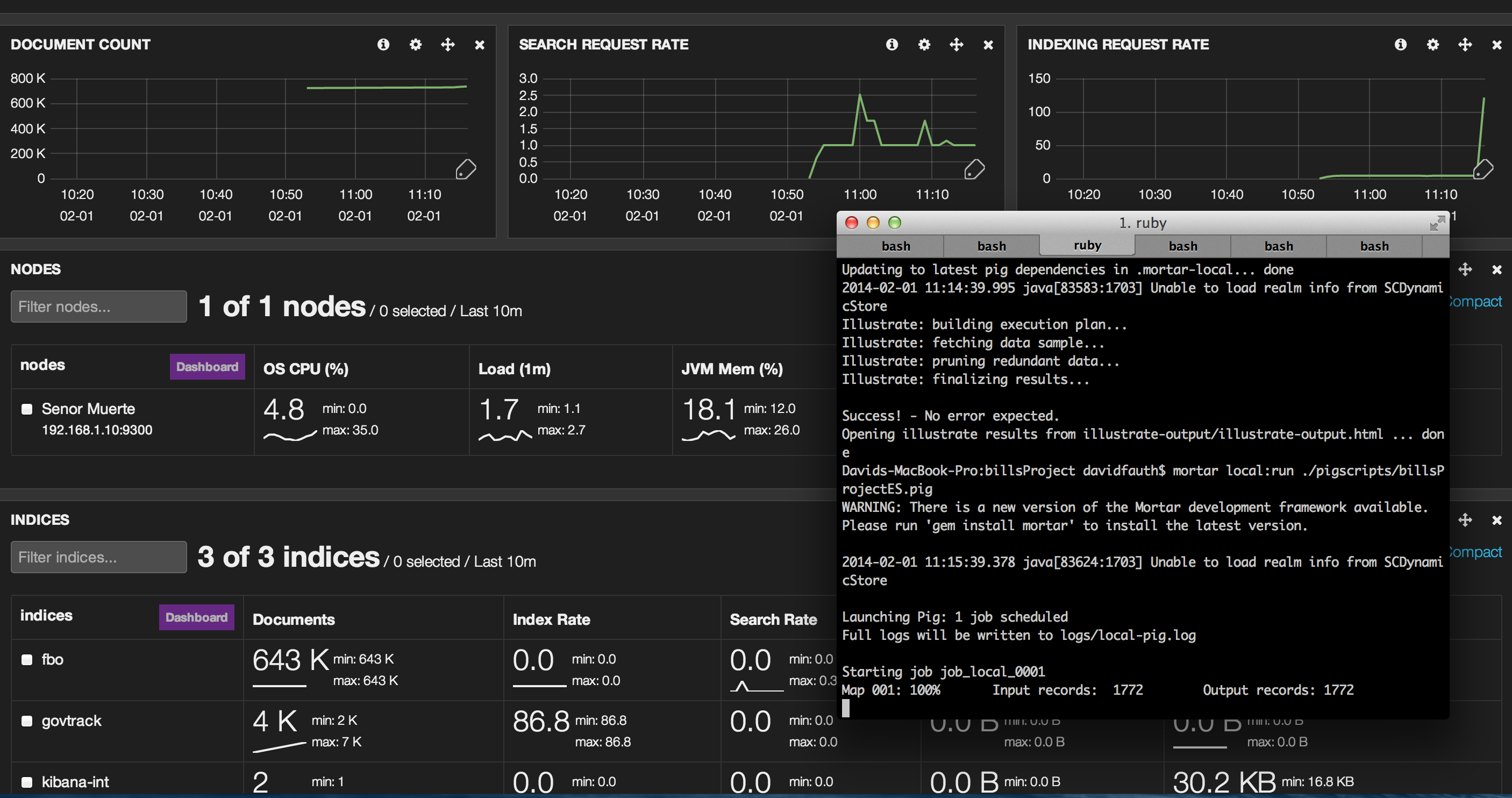
As the Pig job is running in Mortar, we see a third index (“govtrack”) created and you see the document count edge up and the indexing rate shoot up.
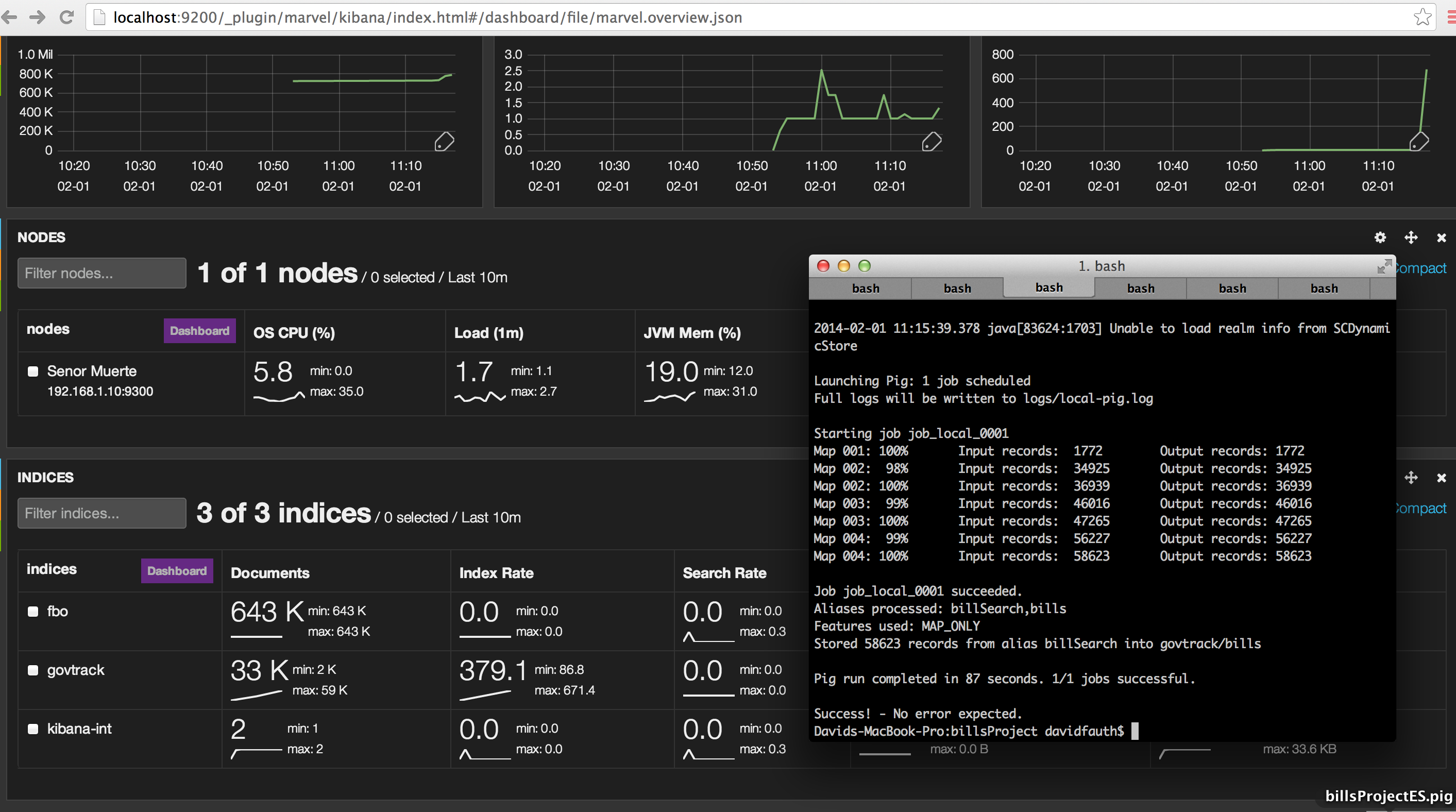
The pig job has finished and we see the uptick in documents indexed. We can also see the indexing rate as well.
This last screen shot shows some later work. I had to drop and recreate an index thus the small dip in documents and the indexing rates. You also see some searches that I ran using Kibana.
In summary, Marvel is a great tool to see what your cluster is doing through the dashboards.
Kibana
Elasticsearch works seamlessly with Kibana to let you see and interact with your data. Specifically, Kibana allows you to create ticker-like comparisons of queries across a time range and compare across days or a rolling view of average change. It also helps you make sense of your data by easily creating bar, line and scatter plots, or pie charts and maps.
Kibana sounded great for visualizing and interactively drilling down into the FBO data set. The installation and configuration is simple. It is a download, unzip, modify a single config.js file and open the URL (as long as you unzipped it so your webserver can load the URL).
Some of the advantages of Kibana are:
You can get answers in real time. In my case, this isn’t as important as if you are doing log file analysis.
You can visualize trends through bar, line and scatter plots. Kibana also provides pie charts and maps.
You can easily create dashboards.
The search syntax is simple.
Finally, it runs in the browser so set-up is simple.
Kibana Dashboard for GovTrack Data
Using Kibana, I’m going create a sample dashboard to analyze the GovTrack bills data. You can read more about the dataset here. In a nutshell, I wanted to see if Kibana can let me drill down on the data and easily look at this data set.
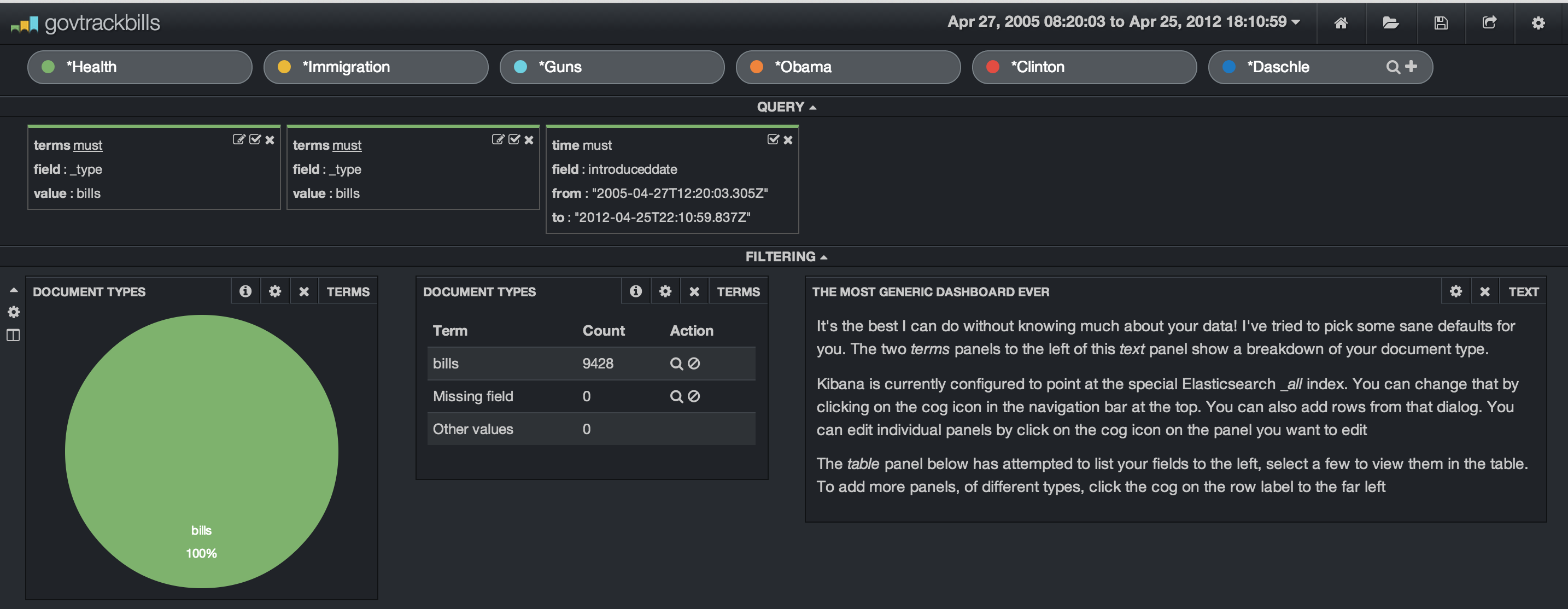
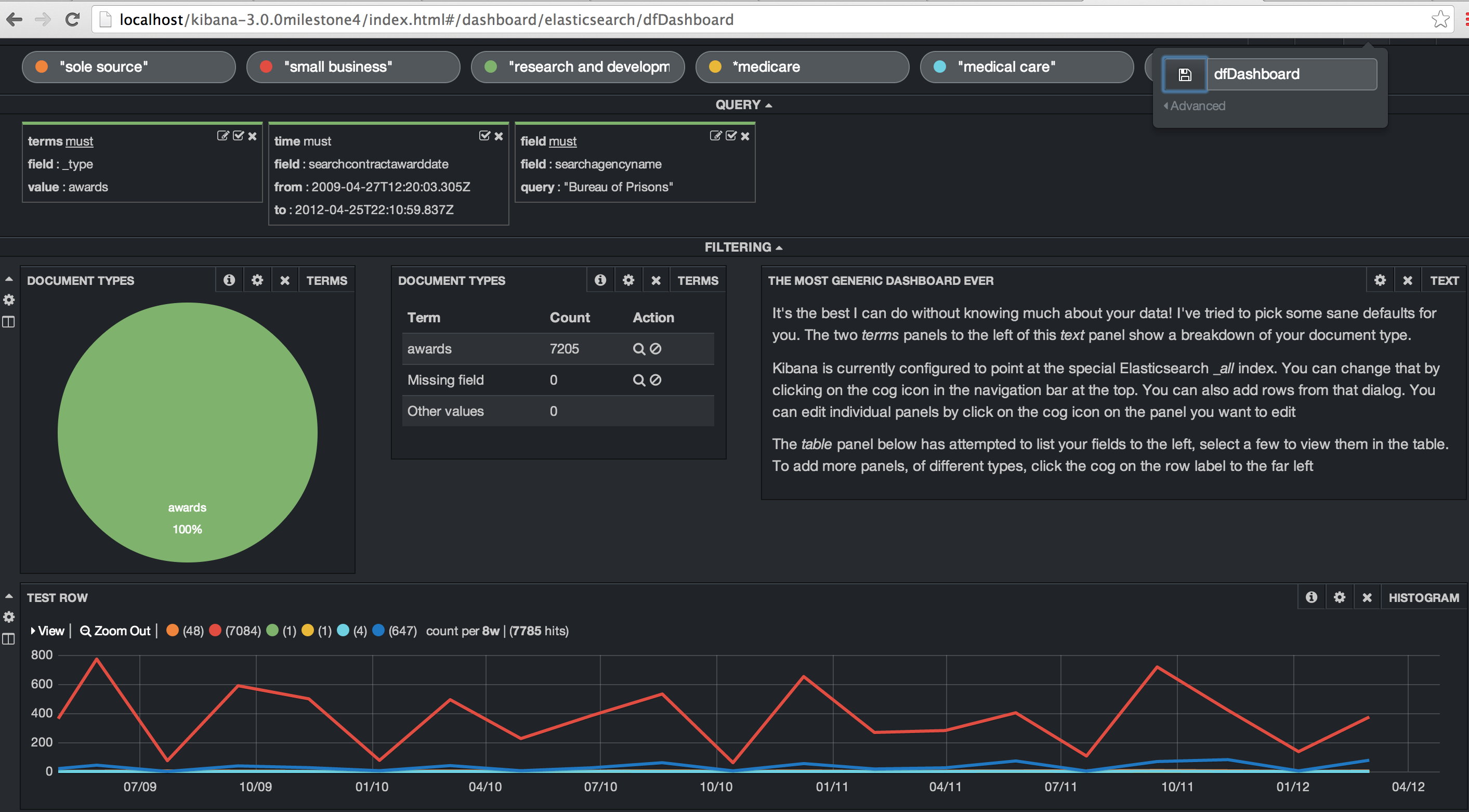
In my dashboard, I’ve set up multiple search terms. I’ve chosen some topics and sponsors of bills. We have Health, Immigration, Guns, Obama, Clinton and Daschle. I’ve added in some filters to limit the search index to the bills and set up a date range. The date range is from 2005 through 2012 even though I only have a couple of years worth of data indexed. We are shown a dataset of 9,428 bills.
Let’s look at an easy way to see when the term “Affordable Care Act” showed up in various bills. This is easily done by adding this as a filter.
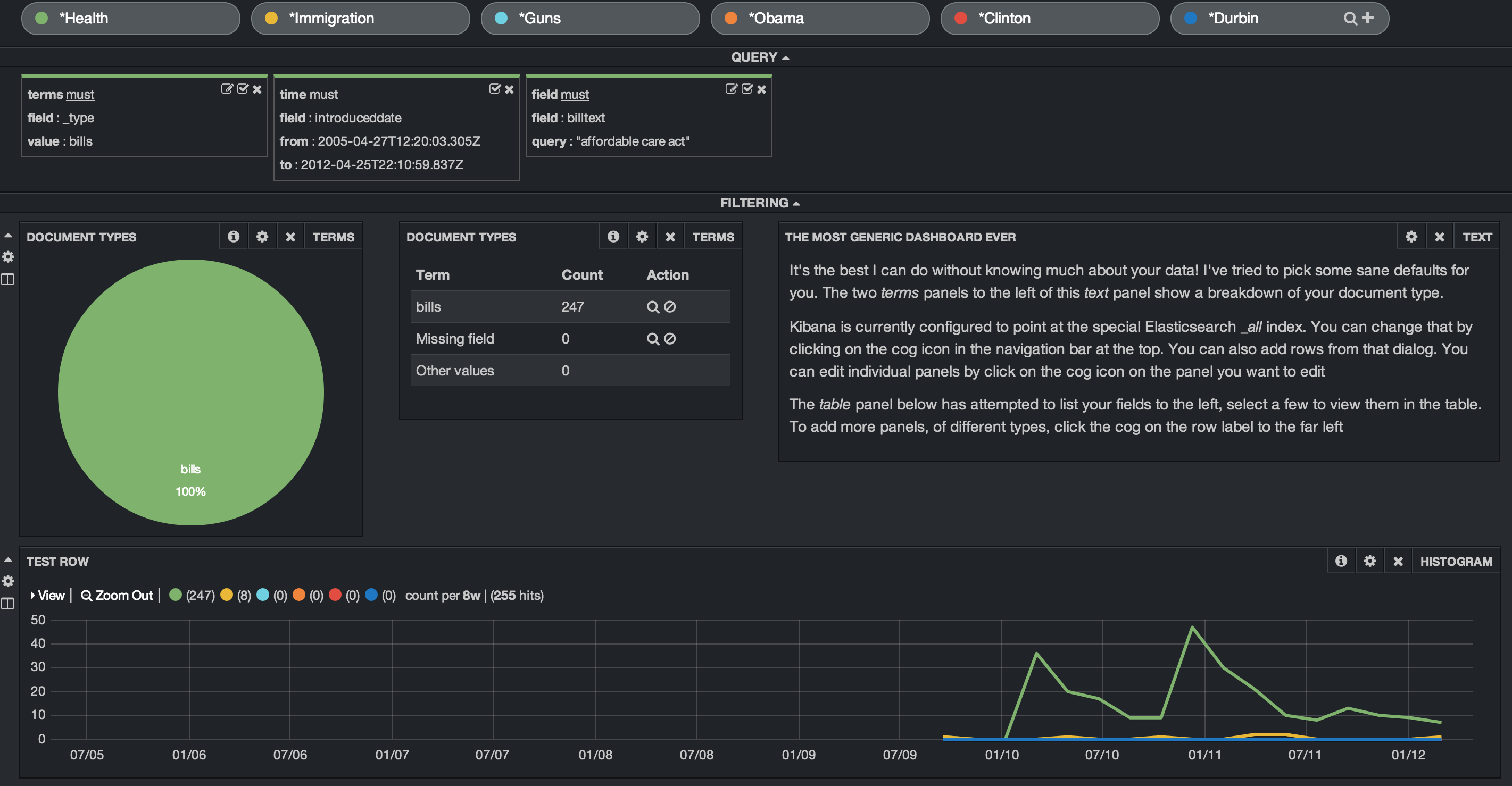
In order to see this over time, we need to add a row and a Histogram panel. In setting up the panel, we set the timefield to the search field “introduceddate”, adjusted the chart settings to show line, legend, x and y axis legends and then choose an interval. I choose an 8 week interval. Once this is added, the histogram will show the bills mentioning the term “Affordable Health Care” in relation to the other search terms. In our example, we see the first mention begin in early 2010 and various bills introduced over the next two years. We also see that the term “immigration” shows up in 8 bills and none of the other search terms appear at all.
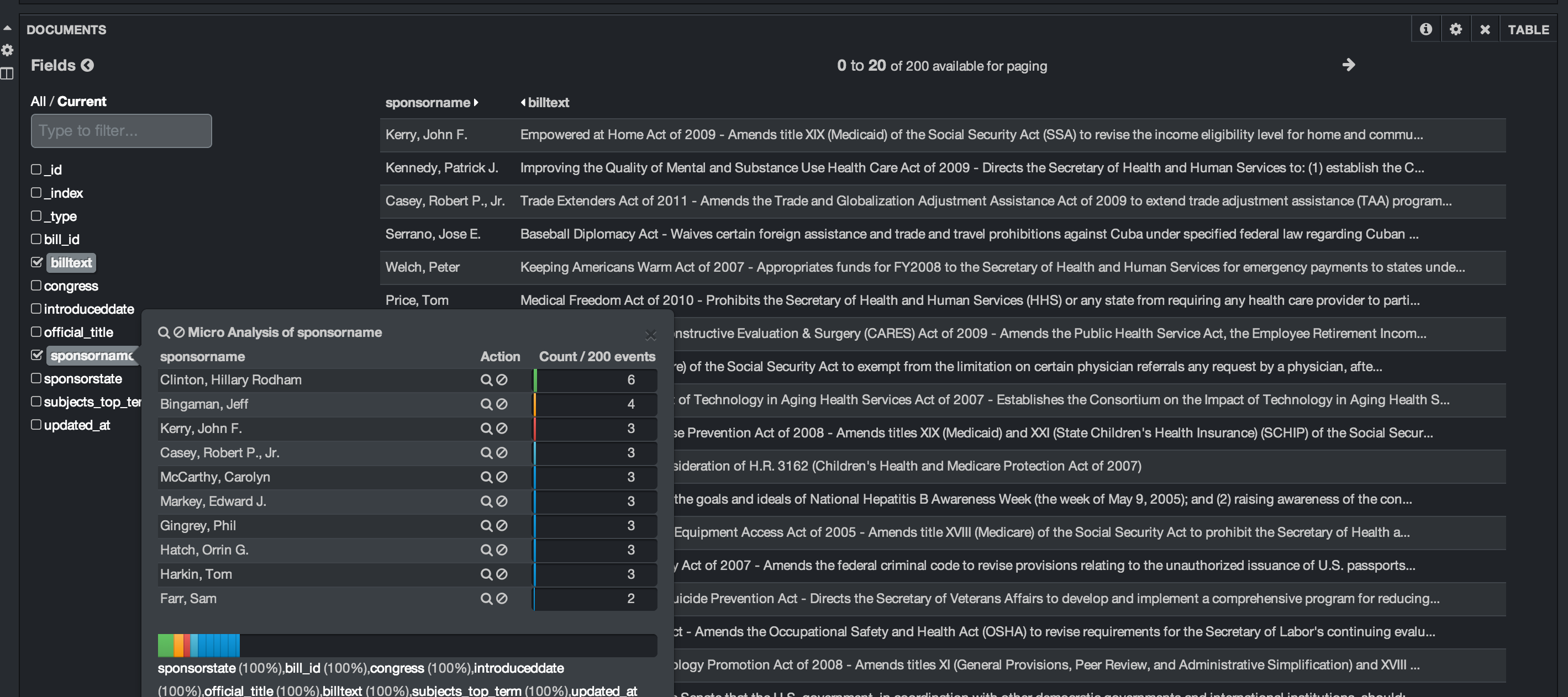
Down below, we add a table panel to allow us to see details from the raw records. We can look at the sponsor, bill text, and other values. Kibana allows us to expand each record, look at the data in raw, json or table format and allows you to select which columns to view. We can also run a quick histogram on any of the fields as shown below. Here I clicked on the bill sponsor to see who is the most common sponsor.
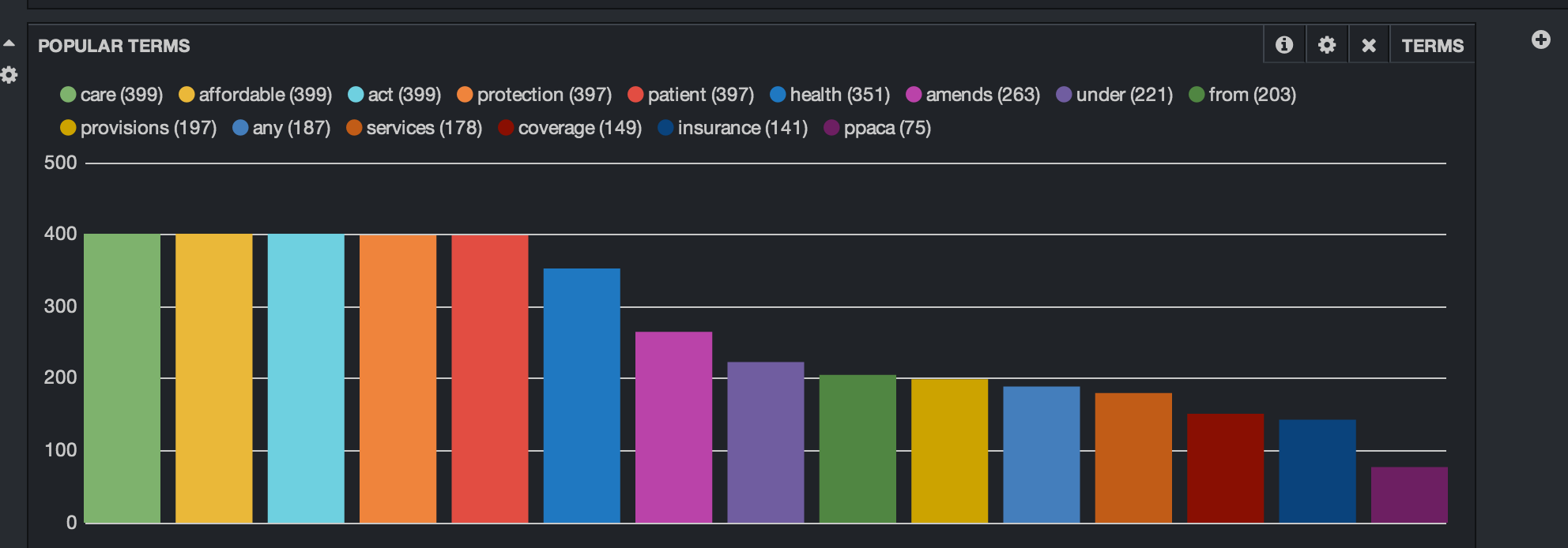
We’ll add one other panel. This is the Popular Terms panel. This shows us by count the most popular terms in the filtered result set. Kibana allows you to exclude terms and set the display as either bar chart, pie chart or a table.
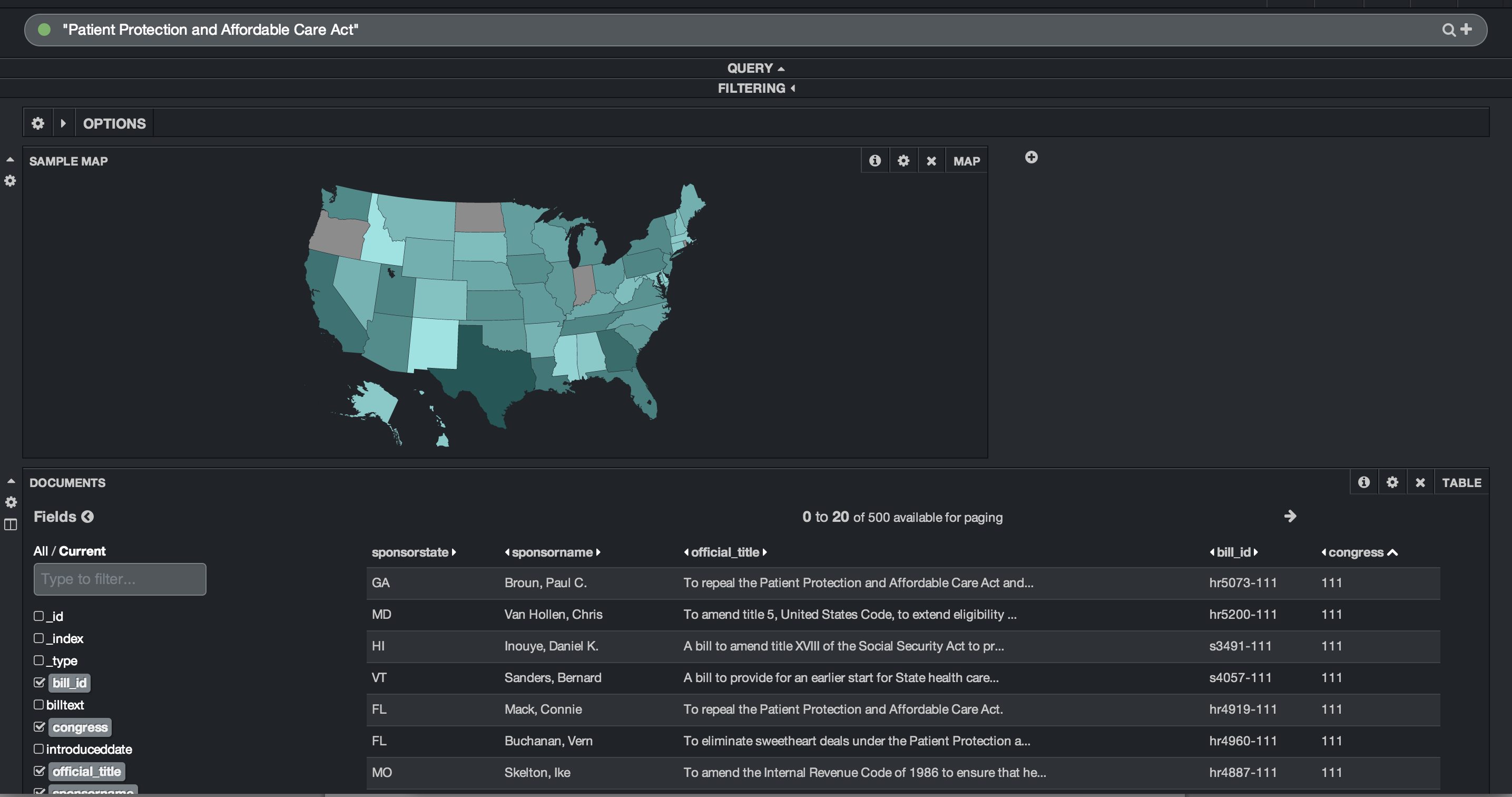
I created another quick dashboard that queries for the term “Patient Protection and Affordable Care Act”. I added a row to the dashboard and added a map panel. The map panel allows you to choose between a world map, US map or European map. Linking the US map to the ‘sponsorstate’ field, I am quickly able to see where the most bills were sponsored that discussed “Patient Protection and Affordable Care Act”. I can also see that Oregon, North Dakota and Indiana had no sponsors. That dashboard is below:
Kibana Dashboard for FBO data
Kibana allows you to create different dashboards for different data sets. I’ll create a dashboard for the FBO data and do some similar queries. The first step is to create the queries for “sole source”, “small business”, “research and development”, “medical care” and “medicare”. I created a time filter on the contract award date and then set the agency name to the “Bureau of Prisons”. Finally, I added in a histogram to show when these terms showed up in the contract description. “Small business” is by far the most popular of those terms.
One of the neat things is that you can easily modify the histogram date range. In this case, I’m using an 8 week window but could easily drill in or out. And you can draw a box within the histogram to drill into a specific date range. Again, so much easier and interactive. No need to re-run a job based on new criteria or a new date range.
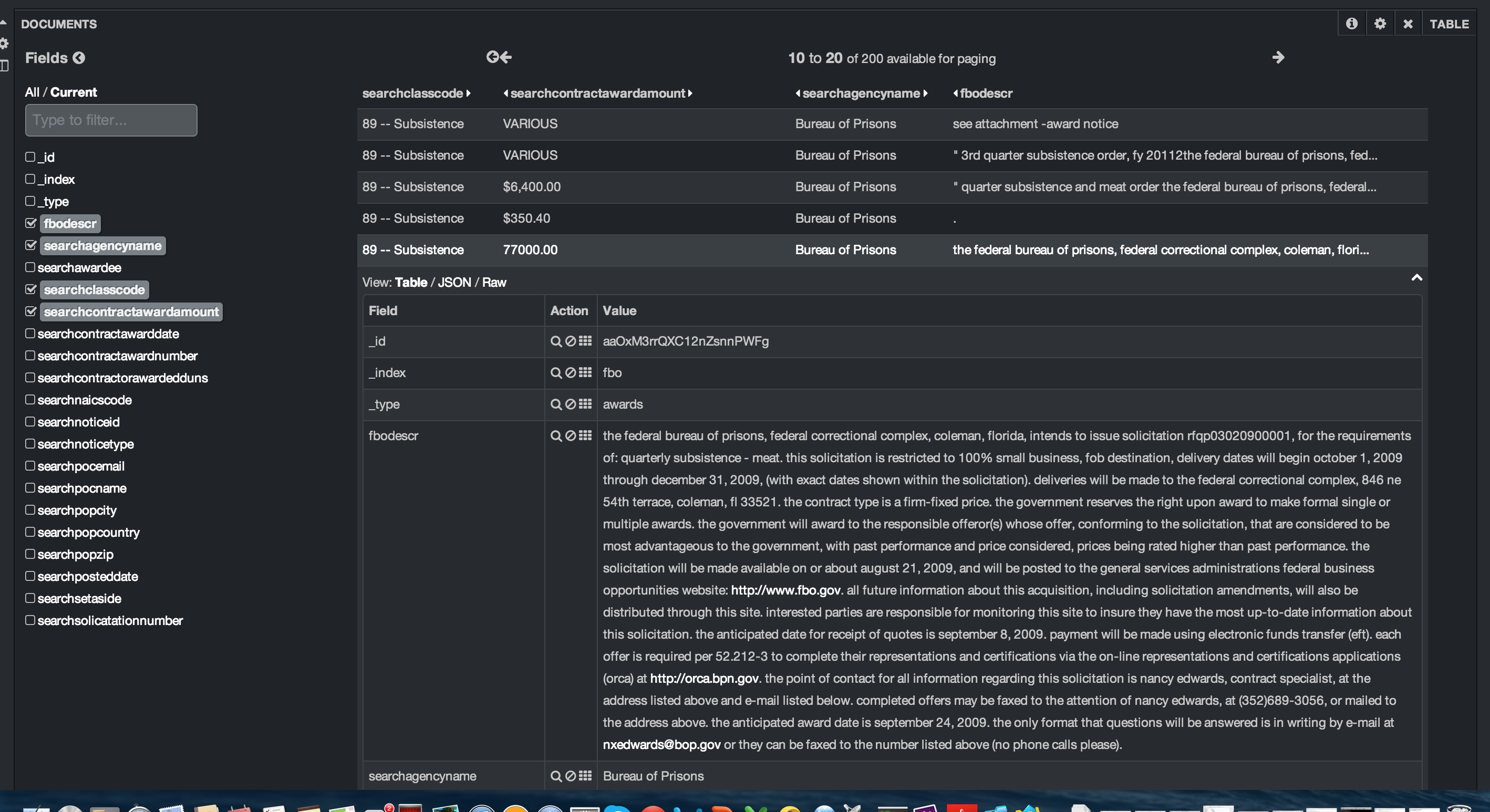
Kibana allows you to page through the results. You can easily modify the number of results and the number of results per page. In this case, I’ve set up 10 results per page with a maximum of 20 pages. You can open each result and see each field’s data in a table, json or raw format.
The so-what
Using Elasticsearch and Kibana with both the FBO and the GovTrack data was great since both had data with a timestamp. While the Elasticsearch stack is normally thought of in the terms of ELK (Elasticsearch, Logstash, and Kibana), using non-logstash data worked out great. Kibana is straight-forward to use and provides the ability to drill down into data easily. You don’t have to configure a data stream or set up a javascript visualization library. All of the heavy lifting is done for you. It is definitely worth your time to check it out and experiment with it.
Earlier this year, Sunlight foundation filed a lawsuit under the Freedom of Information Act. The lawsuit requested solication and award notices from FBO.gov. In November, Sunlight received over a decade’s worth of information and posted the information on-line for public downloading. I want to say a big thanks to Ginger McCall and Kaitlin Devine for the work that went into making this data available.
In the first part of this series, I looked at the data and munged the data into a workable set. Once I had the data in a workable set, I created some heatmap charts of the data looking at agencies and who they awarded contracts to. In part two of this series, I created some bubble charts looking at awards by Agency and also the most popular Awardees.
In the third part of the series, I am going to look at awards by date and then displaying that information in a calendar view. Then we will look at the types of awards.
For the date analysis, we are going to use all of the data going back to 2000. We have six data files that we will join together, filter on the ‘Notice Type’ field, and then calculate the counts by date for the awards. The goal is to see when awards are being made.
The Data Munging
The CSV files contain things like HTML codes and returns within cells. During initial runs, the Piggybank function CSVExcelStorage wasn’t able to correctly parse the CSV files. Other values would end up in the date field and provide inaccurate results. To combat that problem, I ended up finding the SuperCSV java classes. Using their sample code, I was able to write a custom cell processor that would read in the CSV file, strip out carriage returns, and write the information back out in a tab-delimited format.
My friends at Mortar are taking a look at the data and the CSVExcelStorage function to see if my issue can be addressed.
Pig Script
The pig script is really simple. I read in all of the metadata files, filter them where there is an award and it isn’t null. All six files are then joined and a new set of data is generated of just the date of award. These are then grouped and counted. No real rocket science there.
Here is a sample of the results:
Date
Amt
2012-09-28
1190
2009-09-30
1187
2010-09-30
1052
2010-09-29
1027
2009-06-04
1002
Visualization
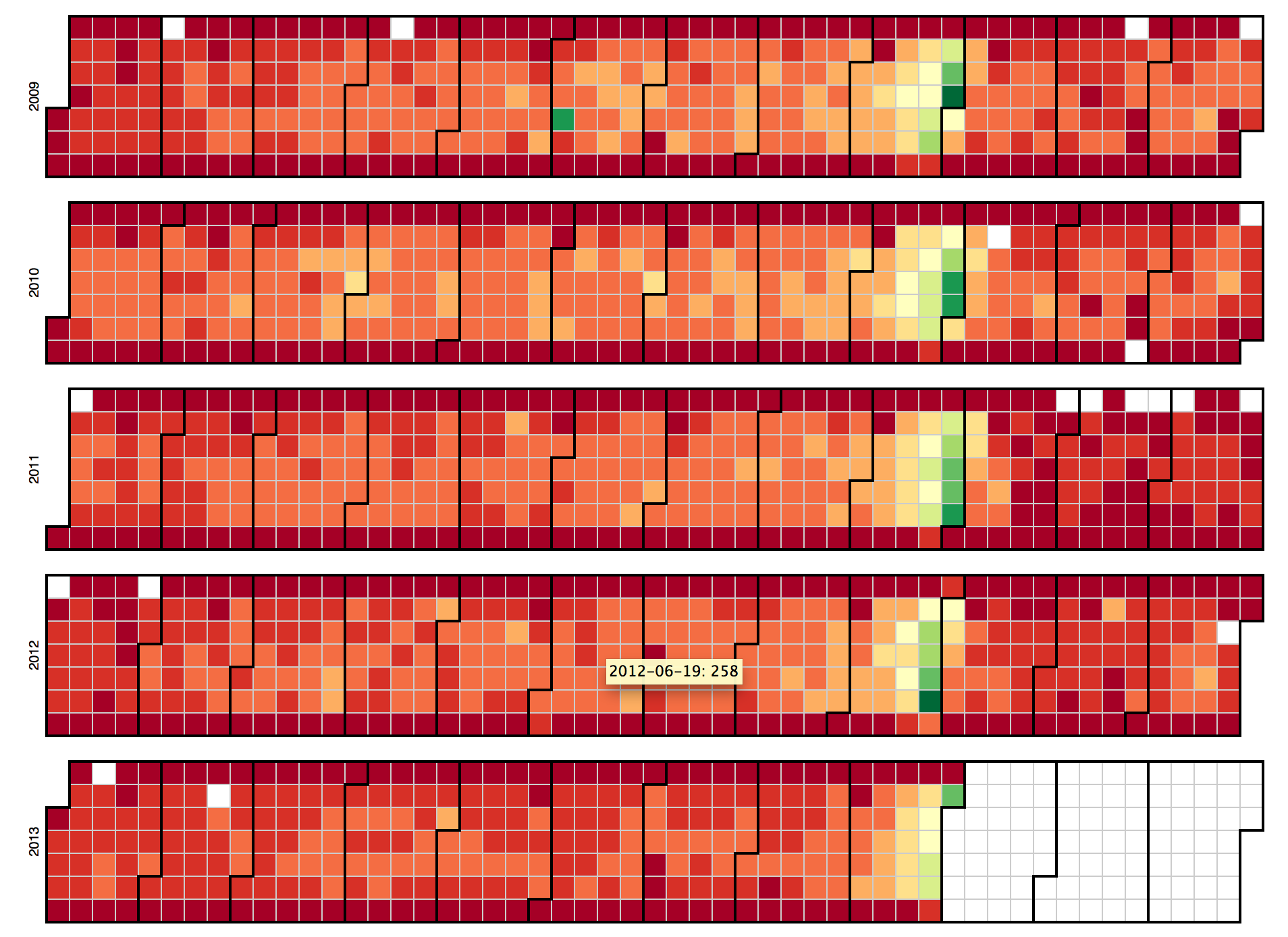
For visualization of this data, I used an adaptation of Mike Bostock’s D3.js calendar example. I used the same colors but made a few tweaks to the scale. A snapshot calendar is below:
In this visualization, larger award counts are green while lower award counts are in red. Anyone familiar with government contracting will notice that “end of the fiscal year” awards are always made in September. Contracting officers need to spend fiscal year money before it expires. In the calendar, it is easy to see this for each of the fiscal years.
Data by Categories
Let’s look at the data by categories. There are 103 unique categories of award types in the data sets. You can see that list here. There are over 9600 combinations of agencies awarding contracts in a category. You can see the CSV file here.
One of the curious categories is the “Live Animals” category. The agency, category and number of awards are listed below:
Agency
Category
Number of Awards
Customs and Border Protection
88 — Live animals
46
National Institutes of Health
88 — Live animals
24
National Park Service
88 — Live animals
9
Centers for Disease Control and Prevention
88 — Live animals
7
Army Contracting Command, MICC
88 — Live animals
6
Office of the Chief Procurement Officer
88 — Live animals
4
United States Marshals Service
88 — Live animals
4
Agricultural Research Service
88 — Live animals
3
Animal and Plant Health Inspection Service
88 — Live animals
3
Food and Drug Administration
88 — Live animals
3
Air Force Materiel Command
88 — Live animals
2
Bureau of Alcohol, Tobacco and Firearms (ATF)
88 — Live animals
2
Forest Service
88 — Live animals
2
Public Buildings Service (PBS)
88 — Live animals
2
TRICARE Management Activity
88 — Live animals
2
U.S. Special Operations Command
88 — Live animals
2
United States Marine Corps
88 — Live animals
2
United States Secret Service (USSS)
88 — Live animals
2
Army Contracting Command
88 — Live animals
1
Bureau of Indian Affairs
88 — Live animals
1
Bureau of Medicine and Surgery
88 — Live animals
1
Direct Reporting Unit – Air Force District of Washington
88 — Live animals
1
Direct Reporting Units
88 — Live animals
1
Farm Service Agency
88 — Live animals
1
FedBid
88 — Live animals
1
Fish and Wildlife Service
88 — Live animals
1
Fresno VAMC
88 — Live animals
1
Office of Acquisitions
88 — Live animals
1
Pacific Air Forces
88 — Live animals
1
San Francisco VAMC
88 — Live animals
1
U.S. Army Corps of Engineers
88 — Live animals
1
VA Connecticut Health Care System
88 — Live animals
1
Washington Headquarters Services
88 — Live animals
1
Bi-Grams in the Description
I decided to take a look at descriptions associated with the awards and see what bi-grams appeared when running this through NLTK. I created a simple Pig script to filter the awards, join them to the descriptions and then run the descriptions through Python/NLTK.
The Python/NLTK piece is below:
Results
A majority (109 out of 192) consisted of “No description provided”. Thus the bi-gram results were “{(description provided),(no description)}”. Of the remaining awards, there were some interesting results. For example:
{(, boarding),(10 paso),(5 potential),(and general),(boarding and)} was from a US Marshals Service Contract for “serives to include the transportation, boarding and general care of 10 paso fino horses”.
{(country of),(of japan),(japan .),(the country),(& removal)} was from a Pacific Air Forces contract for “this is feral pig control & removal service at tama service annex. ”
and then there was this one:
{(for the),(farm hands),(on april),(a contract),(ms. crundwell)}
{(for the),(the horses),(on april),(care for),(ms. crundwell)}
contract was awarded under far 6.302-2, unusual and compelling urgency. on april 17, 2012, rita crundwell, comptroller for the city of dixon, illinois, was arrested by the federal bureau of investigation (fbi) for wire fraud. ms. crundwell was accused of embezzling $53 million from the city of dixon. on april 18, 2012, the u.s. marshals service was notified by the fbi that ms. crundwell’s bank accounts had been frozen. the defendant was using embezzled money for the care and maintenance of over 200 horses located in dixon, illinois and beliot, wisconsin and several additional locations. since her accounts were frozen, the farm/ranch did not have the means to care for the horses. farm hands continued to work after this date even though they were unsure if they would receive payment. if the farm hands were to walk off the job, there would be no means to care for the horses. in addition, weekly deliveries of hay and grain would cease. the usms issued purchase orders for hay and grain deliveries to continue until a contract award could be made for the management and care of the horses. the government recognized that there was an immediate need to care for the animals. if a contract was not awarded immediately, the lives of the horses would be at risk.
You can read about Ms. Crundwell here. There were two contracts awarded for $625,840 and for $302,850 to ensure the horses’ safety.
In summary, I looked at the award dates to look for patterns and then I looked at the text descriptions to look for interesting data combinations.
Earlier this year, Sunlight foundation filed a lawsuit under the Freedom of Information Act. The lawsuit requested solication and award notices from FBO.gov. In November, Sunlight received over a decade’s worth of information and posted the information on-line for public downloading. I want to say a big thanks to Ginger McCall and Kaitlin Devine for the work that went into making this data available.
In the first part of this series, we looked at the data and munging the data into a workable set. Once I had the data in a workable set, I created some heatmap charts of the data looking at agencies and who they awarded contracts to. Those didn’t really work out all that well. Actually they sucked. They didn’t represent the data well at all. The data was too sparsely related so I was forced to show more data than really made sense. In part two of this post, we will create some bubble charts looking at awards by Agency and also the most popular Awardees.
The Data
For this analysis, we are going to use all of the data going back to 2000. We have six data files that we will join together, filter on the ‘Notice Type’ field and then calculate the sum and count values by the awarding agency and by the awardee.
Pig Script
Again, I created a Mortar project to process the data. The pig script loads the six tab delimited files, filters the files by ‘(noticeType == ‘Award Notice’ AND contractAwardAmount IS NOT NULL)’, does a union and then calculates the count and sum values. I used a small piece of Python code to clean up the award amount field.
The results are written out to a delimited file. Looking at the results, there were 465 agencies that awarded a total of 428,937 contracts. Again, this is for all of the available data (2000-present). For awardees, there were over 192,000 unique names receiving awards.
Visualization
For this visualization, I wanted to try a bubble chart. The bubble chart will allow me to visualize the number of awards, the size of awards and a relative size based on the number of awards.
For the bubble chart, I am using HighCharts, a javascript library for creating charts. Since this is a personal, non-commercial website, there is no charge to use the product.
Here is a sample of the results for agency awards:
Agency
Number of Awards
Sum of Award Amount
DLA Acquisition Locations
119231
34758490026.0626
Naval Supply Systems Command
42013
1330565313323460
Army Contracting Command
40464
162850429349.624
Air Force Materiel Command
37267
16473214961095.8
U.S. Army Corps of Engineers
17032
211563631159.529
And here’s a sample of the results for awardees:
Agency
Number of Awards
Sum of Award Amount
KAMPI COMPONENTS CO., INC.-7Z016 KAMPI COMPONENTS CO., INC. 88 CANAL RD FAIRLESS HILLS PA 19030-4302 US
1312
89038206.8847656
OSHKOSH CORPORATION-45152 OSHKOSH CORPORATION 2307 OREGON ST OSHKOSH WI 54902-7062 US
1017
159693165.185546
PIONEER INDUSTRIES, INC.-66200 PIONEER INDUSTRIES, INC. 155 MARINE ST FARMINGDALE NY 11735-5609 US
975
58782020.125
BELL BOEING JOINT PROJECT OFFICE, AMARILLO, TX 79120-3160
940
465747753
Let’s look at a simple bar chart of the Agency Awards:
Now, let’s look at the bubble chart of the same data:
Here is a simple bar chart of award recipients:
And a bubble chart showing awards by recipients:
Analysis
There really isn’t a lot of surprise in which agencies are awarding contracts. 8 of the top 10 are in the defense industry. Similarily the top recipient of contracts was Kampi Components, which supplies factory replacement spare parts to the United States military. Number two was Oshkosh Corporation, who are manufacturers of severe heavy duty all wheel drive defense or military trucks, aircraft or emergency rescue and firefighting. The one outlier is NIH which didn’t award a large number of contracts but awarded large contracts.
Next steps will be to look at the types of awards and see how to display those in a meaningful fashion.
Earlier this year, Sunlight foundation filed a lawsuit under the Freedom of Information Act. The lawsuit requested solication and award notices from FBO.gov. In November, Sunlight received over a decade’s worth of information and posted the information on-line for public downloading. I want to say a big thanks to Ginger McCall and Kaitlin Devine for the work that went into making this data available.
From the Sunlight page linked above:
“The notices are broken out into two parts. One file has records with the unique id for each notice, and almost all of the related data fields. The other file with the _desc suffix has the unique id for each notice and a longer prose field that includes the description of the notice. Additionally, the numbers at the end of each file name indicate the year range.” So what we have are two files for each year. One file has the metadata about the solicitation and award and the other related file has the verbage about the notice.
The metadata consists of the following rows:
Posted Date
Class Code
Office Address Text
Agency Name
POC Name
POC Text
Solicitation Number
Response Deadline
Archive Date
Additional Info Link
POC Email
Set Aside
Notice Type
Contract Award Number
Contract Award Amount
Set Aside
Contract Line Item Number
Contract Award Date
Awardee
Contractor Awarded DUNS
JIA Statutory Authority
JA Mod Number
Fair Opportunity JA
Delivery Order Number
Notice ID
The metadata file is a .CSV approximately 250-300MB in size. It is a relatively large file that isn’t easily manipulated in Excel. Additionally, it has embedded quotes, commas, html code and multiple lines with returns in the field. For file manipulation, I decided to use Vertascale. Vertascale is designed to provide real-time insights for data professionals on data stored in S3, Hadoop or on your desktop. It can easily handle text, json, zip, and a few other formats.
The decision to use Vertascale was driven by the size of the file, the ability for it to read the file correctly (i.e. parse the file correctly) and the ability to transform the data out into a format that I could use with other tools. Let’s run through how Vertascale can do this quickly and easily:
A) Opening & converting raw data into a more useful format
Step 1: Open the Vertascale application and navigate to the file that is on my local machine. In this case, we will use:
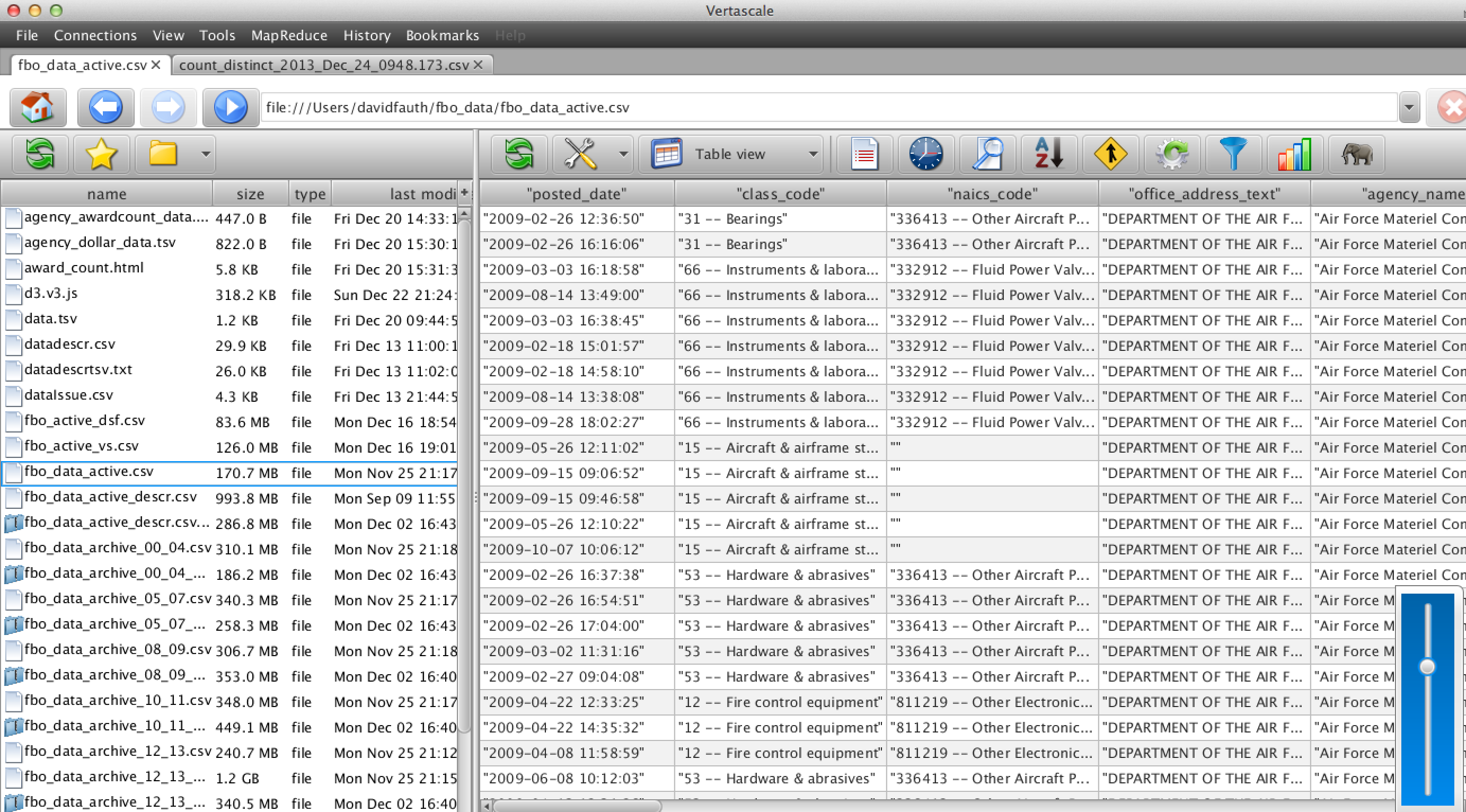
Step 2: Next, use Vertascale’s built in parsing tools to convert the file into a more user friendly view:
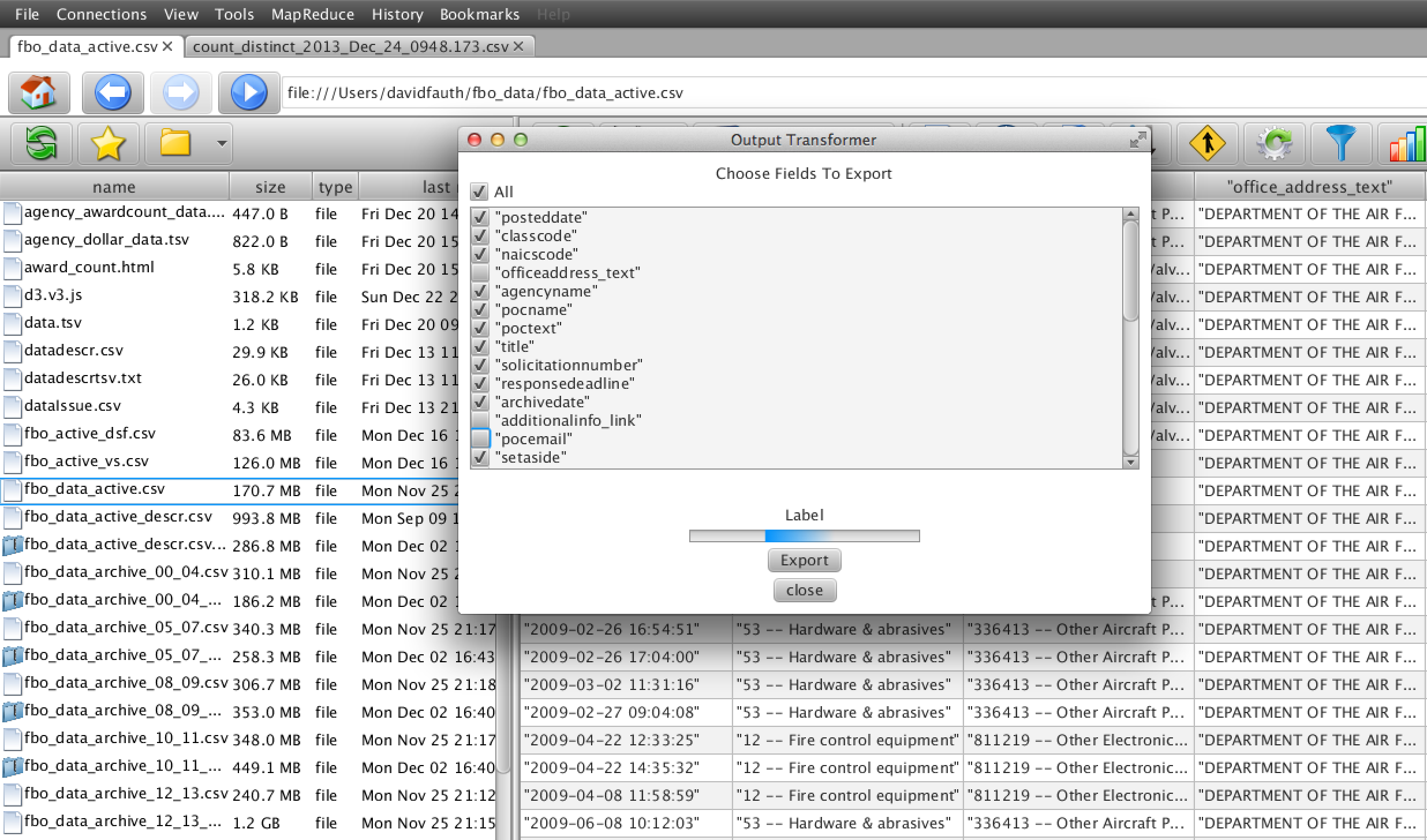
Step 3: Export the columns into a file that we can use later.
B) Getting a feel for the data
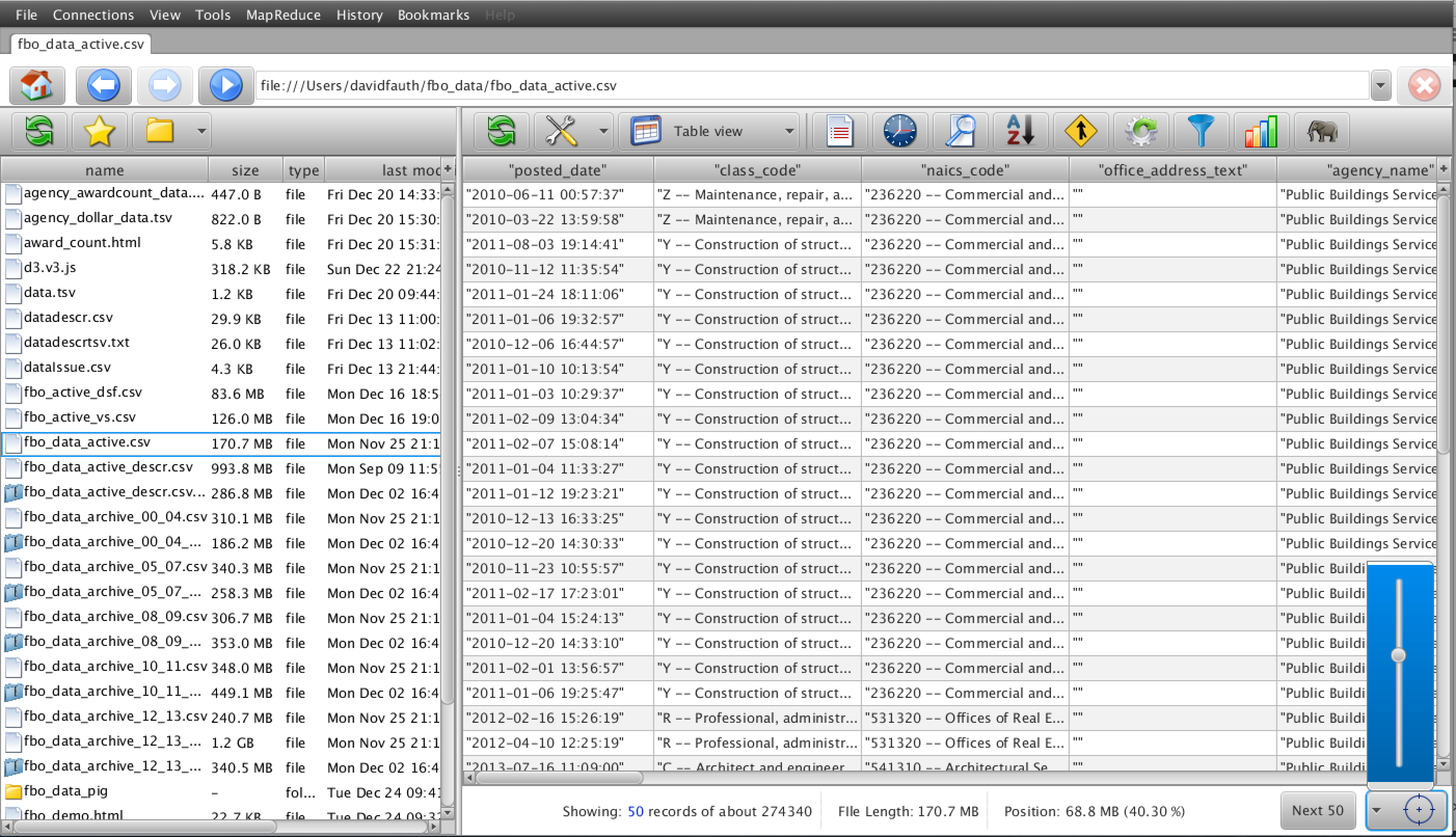
Now that the data is loaded in Vertascale (which can be an overwhelming task at times), we can explore and analyze the data. We will look at the Browse and the Count feature of Vertascale to understand the data.
1) Browse
I used Vertascale’s built-in data browser to browse through the dataset to see what data was available. With the slider and next 50 options, I could quickly go to any spot in the file and see what the data was available.
2) Count
I wanted to look at the “Set aside” column to see what the distribution of set aside values where in the file. Using the “Count Distinct” function, I was able to see how those values were distributed across the entire file. In this case, we can see
Next Steps
At this point, we have retrieved the FBO datafiles, used Vertascale to get a feel for what is in the files, extracted columns out to do some initial analysis. In the next post, we’ll dive in a little more to look at some ways of analyzing and visualizing this data.